gint : un noyau pour développer des add-ins
Posté le 20/02/2015 17:30
 Ce topic fait partie de la série de topics du fxSDK.
Ce topic fait partie de la série de topics du fxSDK.
En plus des options de programmation intégrée comme le Basic Casio ou Python, la plupart des calculatrices Casio supportent des
add-ins, des programmes natifs très polyvalents avec d'excellentes performances. Les add-ins sont généralement programmés en C/C++ avec l'aide d'un ensemble d'outils appelé SDK.
Plusieurs SDK ont été utilisés par la communauté avec le temps. D'abord le
fx-9860G SDK de Casio avec fxlib pour Graph monochromes (plus maintenu depuis longtemps). Puis le
PrizmSDK avec libfxcg pour Prizm et Graph 90+E (encore un peu actif sur Cemetech). Et plus récemment celui que je maintiens, le
fxSDK, dont gint est le composant principal.
gint est un unikernel, ce qui veut dire qu'il embarque essentiellement un OS indépendant dans les add-ins au lieu d'utiliser les fonctions de l'OS de Casio. Ça lui permet beaucoup de finesse sur le contrôle du matériel, notamment la mémoire, le clavier, l'écran et les horloges ; mais aussi de meilleures performances sur le dessin, les drivers et la gestion des interruptions, plus des choses entièrement nouvelles comme le moteur de gris sur Graph monochromes.

Les sources de gint sont sur la forge de Planète Casio :
dépôt Gitea Lephenixnoir/gint
Aperçu des fonctionnalités
Les fonctionnalités phares de gint (avec le fxSDK) incluent :
- Toutes vos images et polices converties automatiquement depuis le PNG, sans code à copier (via fxconv)
- Un contrôle détaillé du clavier, avec un GetKey() personnalisable et un système d'événements à la SDL
- Une bibliothèque standard C plus fournie que celle de Casio (voir fxlibc), et la majorité de la bibliothèque C++
- Plein de raccourcis pratiques, comme pour afficher la valeur d'une variable : dprint(1,1,"x=%d",x)
- Des fonctions de dessin, d'images et de texte optimisées à la main et super rapides, surtout sur Graph 90+E
- Des timers très précis (60 ns / 30 µs selon les cas, au lieu des 25 ms de l'OS), indispensables pour les jeux
- Captures d'écran et capture vidéo des add-ins par USB, en temps réel (via fxlink)
Avec quelques mentions spéciales sur les Graph monochromes :

Un moteur de gris pour faire des jeux en 4 couleurs !
La compatibilité SH3, SH4 et Graph 35+E II, avec un seul fichier g1a
Une API Unix/POSIX et standard C pour accéder au système de fichiers (Graph 35+E II seulement)
Et quelques mentions spéciales sur les Graph 90+E :

Une nouvelle police de texte, plus lisible et économe en espace
Le dessin en plein écran, sans les bordures blanches et la barre de statut !
Un driver écran capable de triple-buffering
Une API Unix/POSIX et standard C pour accéder au système de fichiers
Galerie d'add-ins et de photos
Voici quelques photos et add-ins réalisés avec gint au cours des années !


Arena (2016) — Plague (2021)
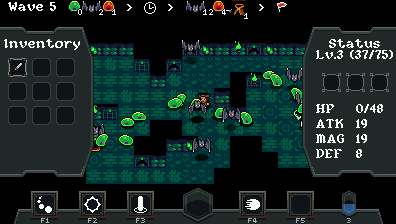
Rogue Life (2021)
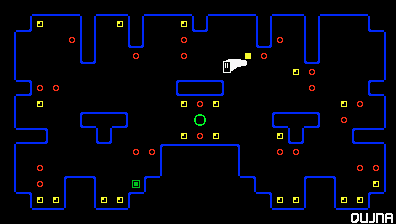
Momento (2021)
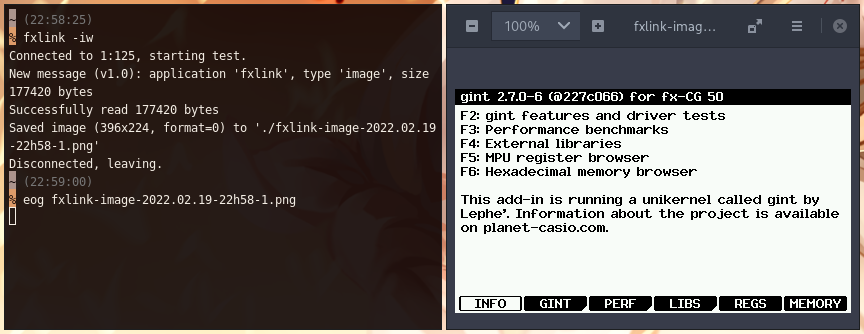
Communication avec le PC (cliquez pour agrandir)
Utiliser gint pour développer des add-ins
Les instructions pour installer et utiliser gint sont données dans les divers tutoriels recensés dans le
topic du fxSDK. Il y a différentes méthodes de la plus automatique (GiteaPC) à la plus manuelle (compilation/installation de chaque dépôt). Le fxSDK est compatible avec Linux, Mac OS, et marche aussi sous Windows avec l'aide de WSL, donc normalement tout le monde est couvert

Notez en particulier qu'il y a des
tutoriels de développement qui couvrent les bases ; tout le reste est expliqué dans les en-têtes (fichiers
.h) de la bibliothèque que vous pouvez
consulter en ligne, ou dans les ajouts aux changelogs ci-dessous.
 Changelog et informations techniques
Changelog et informations techniques
Pour tester les fonctionnalités et la compatibilité de gint, j'utilise un add-in de test appelé gintctl (
dépôt Gitea Lephenixnoir/gintctl). Il contient aussi une poignée d'utilitaires d'ordre général.
Ci-dessous se trouve la liste des posts indiquant les nouvelles versions de gint, et des liens vers des instructions/tutoriels supplémentaires qui accompagnent ces versions.
Anecdotes et bugs pétés
Ô amateurs de bas niveau, j'espère que vous ne tomberez pas dans les mêmes pièges que moi.
TODO list pour les prochaines versions (2023-04-03)
gint 2.11
- Changements de contextes CPU. À reprendre du prototype de threading de Yatis pour permettre l'implémentation d'un véritable ordonnanceur. Demandé par si pour faire du threading Java.
- Applications USB. Ajouter le support de descripteurs de fichiers USB. Potentiellement pousser jusqu'à avoir GDB pour debugger.
- Support de scanf() dans la fxlibc. Codé par SlyVTT, plus qu'à nettoyer et fusionner.
Non classé
- Regarder du côté serial (plus facile que l'USB) pour la communication inter-calculatrices (multijoueur) et ultimement l'audio (libsnd de TSWilliamson).
- Un système pour recompiler des add-ins mono sur la Graph 90+E avec une adaptation automatique.
- Support des fichiers en RAM pour pouvoir utiliser l'API haut-niveau sur tous les modèles et éviter la lenteur de BFile à l'écriture quand on a assez de RAM.


Citer : Posté le 08/09/2019 17:38 | #
Excellent ! Tout devrait tomber en place rapidement.
Citer : Posté le 08/09/2019 17:59 | #
En fait, je rencontre un nouveau problème, en incluant respectivement les dossiers include et lib avec -I et -L.
:: Making into build-fx
sh4eb-nofpu-elf-gcc -o build-fx/src/Piles.elf build-fx/src/main.o -mb -ffreestanding -nostdlib -Wall -Wextra -fstrict-volatile-bitfields -std=c11 -Os -I/home/user/Documents/src/casio/include -L/home/user/Documents/src/casio/lib -m4-nofpu -DFX9860G -Tfx9860g.ld -lgint-fx -lgcc -Wl,-Map=build-fx/map
/home/user/Documents/src/casio/lib/gcc/sh4eb-nofpu-elf/8.3.0/../../../../sh4eb-nofpu-elf/bin/ld: cannot open linker script file fx9860g.ld: No such file or directory
collect2: error: ld returned 1 exit status
Makefile:73: recipe for target 'Test.g1a' failed
make: *** [Test.g1a] Error 1
Visiblement il ne trouve pas le fichier fx9860g.ld
EDIT: "fx9860g.ld" est dans le dossier bin de mon préfix custom, le même dossier que "libgint-fx.a"
Ajouté le 08/09/2019 à 18:06 :
En fait, c'est bon il suffisait d'utiliser le dossier "bin" au lieu du dossier "lib" pour l'option "-L"
Citer : Posté le 08/09/2019 18:06 | #
Ah, intéressant ! Il faut visiblement spécifier explicitement -L au linker pour ajouter un répertoire personnalisé à la recherche du linker script. Essaie avec -Xlinker -L -Xlinker <folder> en plus.
Edit : Okay, tant mieux !
Citer : Posté le 08/09/2019 21:37 | #
Une petite question, comment puis-je faire des syscalls avec fxsdk, gint et gcc? La méthode pour le SDK casio ne fonctionne pas...
Citer : Posté le 08/09/2019 21:56 | #
On les fait proprement en assembleur. La méthode utilisée en C avec le SDK est une aberration...
Il y a plein d'exemples ici : https://gitea.planet-casio.com/Lephenixnoir/gint/src/branch/compat/src/core/syscalls.S
Fais gaffe à ce que tu appelles ; s'il y a un équivalent gint alors il faut définitivement utiliser cet équivalent. Si tu arrives ou n'arrives pas à utiliser des syscalls, je veux bien savoir ; les limites de ce qui est compatible sont encore floues.
Citer : Posté le 08/09/2019 22:10 | #
En fait j'ai créé un fichier "syscalls.S" avec ce code:
.section ".pretext"
#define syscall(id) \
mov.l syscall_table, r2 ;\
mov.l 1f, r0 ;\
jmp @r2 ;\
nop ;\
1: .long id
_battery:
syscall(0x39C)
Mais à la compilation il ne trouve pas le fichier en assembleur.
Citer : Posté le 08/09/2019 22:18 | #
Ah, mais c'est que j'ai pas mis les règles assembleur. Fiouh...
J'ai poussé sur le dépôt du fxSDK une nouvelle version du Makefile avec les règles appropriées. Pour l'utiliser, il suffit normalement (mais pas pour toi) de pull le dépôt et réinstaller le fxSDK, puis taper fxsdk update dans le dossier de ton projet.
Sauf que tu as modifié le Makefile, et la dernière commande l'écraserait. Tu veux certainement pas repartir de zéro. Tu peux faire la dernière étape à la main en récupérant les nouvelles règles ici : https://gitea.planet-casio.com/Lephenixnoir/fxsdk/commit/4f145cb202ae7104e12ba2e1f6d49e93dc2e6fa0
Je réalise que mon Makefile n'est pas vraiment flexible, il est issu de celui de gintctl et ne permet pas du tout de changer de toolchain facilement. Il faut que j'en fasse un plus souple.
Citer : Posté le 08/09/2019 22:19 | #
Ok merci !
Citer : Posté le 09/09/2019 09:26 | #
- A la compilation de gint, j'ai dû changer le fichier fxconv.py qui est dans le PATH en modifiant la déclaration de la fonction "elf" en ligne 673:
Voilà, j'ai poussé sur le dépot du fxSDK un nouveau commit introduisant les options appropriées pour fxconv :
• --toolchain pour spécifier la toolchain à utiliser (eg. sh3eb-elf)
• --arch pour spécifier l'architecture cible (eg. sh3 ou sh4-nofpu)
• --section pour spécifier la section cible (eg. .rodata)
Ça devrait résoudre ton problème de façon plus élégante.
Ajouté le 13/09/2019 à 08:21 :
Encore une modification importante aujourd'hui !
Après avoir ajouté les gestionnaires d'exceptions (les System ERROR si vous voulez), on m'a suggéré de permettre au programmeur d'afficher les infos qu'il voulait. J'ai donc ajouté une fonction gint_panic_set() que l'on peut appeler pour choisir sa propre fonction pour debugger en cas d'erreur. Typiquement vous voudrez afficher plein d'infos à l'écran... voire scroller avec getkey().
(Détail technique : l'ancien panic tournait dans le gestionnaire d'exceptions, et ne pouvait donc pas utiliser d'interruptions. Donc pas de getkey(), pas de sleep(), plein de trucs limitants. Désormais je rte directement dans le panic, ce qui signifie que le panic peut utiliser toutes les fonctions. Techniquement parlant c'est une bonne avancée !)
En plus de ça, j'ai ajouté un mécanisme permettant de rattraper les exceptions. J'en ai besoin pour mon inspecteur de mémoire dans gintctl. En effet, dès qu'on se met sur une adresse invalide, ça fait une TLB error et l'add-in plante. Ce mécanisme permet d'être informé que l'erreur s'est produite et de continuer quand même l'exécution. Ainsi, l'add-in reprend, réalise qu'il a été informé d'une erreur, et affiche "TLB error" à toutes les adresses invalides.
Citer : Posté le 13/09/2019 11:29 | #
En plus de ça, j'ai ajouté un mécanisme permettant de rattraper les exceptions. J'en ai besoin pour mon inspecteur de mémoire dans gintctl. En effet, dès qu'on se met sur une adresse invalide, ça fait une TLB error et l'add-in plante. Ce mécanisme permet d'être informé que l'erreur s'est produite et de continuer quand même l'exécution. Ainsi, l'add-in reprend, réalise qu'il a été informé d'une erreur, et affiche "TLB error" à toutes les adresses invalides.
Rattraper des exceptions ?
Mais, c'est à dire que à terme, même après une exception un addin pourra continuer à s'exécuter ? Mais c'est fantastique ça
Par contre, sinon, j'ai toujours quelques problèmes autour du DMA, lorsque je lance DMA memset, ma calculatrice freeze
Projet de jeu multijoueur : 1V1 3D
Une lib de debug simple : la liblog
Citer : Posté le 13/09/2019 11:32 | #
Mais, c'est à dire que à terme, même après une exception un addin pourra continuer à s'exécuter ? Mais c'est fantastique ça
Ben, pas vraiment. Si l'add-in fait un accès mémoire illégal et qu'on continue l'exécution, le registre de destination contiendra une valeur complètement arbitraire. Ça ne marche que si l'add-in prévoit que l'accès peut échouer et le détecte. C'est donc très marginal.
Fichtre, va falloir que je regarde tout ça en détail.
Ajouté le 14/09/2019 à 10:12 :
Par contre, sinon, j'ai toujours quelques problèmes autour du DMA, lorsque je lance DMA memset, ma calculatrice freeze
Je peux reproduire sur ma Graph 75+E en 02.05.2201, je vais enquêter.
Ajouté le 14/09/2019 à 16:21 :
J'ai implémenté un outil de visualisation pour le DMA dans gintctl, et le freeze se produit dès que j'utilise un transfert sans interruptions. Par ailleurs j'ai du mal à lire/écrire correctement dans les registres du DMA.
Ajouté le 14/09/2019 à 17:36 :
Tous les registres sont à 0, je commence à me demander s'il y a un DMA. Ce qui expliquerait pourquoi ça freeze en mode sans interruption vu qu'il attend immédiatement explicitement la fin du transfert qui de toute façon n'existe pas.
Citer : Posté le 14/09/2019 18:28 | #
Peut être que les adresses du dma ne sont pas les mêmes
Projet de jeu multijoueur : 1V1 3D
Une lib de debug simple : la liblog
Citer : Posté le 14/09/2019 18:31 | #
J'ai tenté toutes les adresses connues de modules DMA de SimLo sans succès.
Ce serait la première différence majeure découverte entre les SH7305 qui équipent les Graph mono et les Graph 90+E.
D'un côté, la doc de SimLo ne concerne que des SH3 et la Prizm. Or, la Prizm a définitivement besoin d'un DMA sinon l'écran ne tient pas la performance. Il n'est pas impossible que Casio ait éliminé le DMA du design des Graph mono pour économiser.
J'ai en tête une idée pour détecter expérimentalement les registres dans l'espace d'adressage, mais c'est tordu et ça pourrait être dangereux sur les bords. Pour l'instant je ne vois pas où aller d'autre.
Ajouté le 15/09/2019 à 12:29 :
J'ai continué d'enquêter avec le DMA sur Graph 90.
Jusqu'ici je n'arrive pas à exécuter dma_memcpy() proprement, le transfert se conclut sans erreur mais les données à l'arrivée sont fausses. De plus, on ne gagne quasiment rien.
Pour vous donner une idée, afficher une image en R5G6B5 (le format le plus rapide à afficher mais le moins compact) prend 24.7 ms en processeur pur, et le transfert équivalent (mais qui produit des mauvaises données pour l'instant) prend 21.3 ms. En montant l'overclock au maximum, ces temps descendent à 16.5 ms et 14.8 ms.
C'est assez décevant. J'aimerais comprendre plus finement les relations entre les fréquences des différentes mémoires présentes, et tenter d'exploiter des techniques un peu plus tordues pour l'accélérer. 40 FPS avec triple-buffering juste pour une image en plein écran, c'est vraiment pas extraordinaire.
Pour référence, je pense actuellement à utiliser les mémoires IL (4k), X (8k) et Y (8k) qui sont des bouts de mémoire normalement plus rapides que la RAM. Ça peut pas faire des miracles car il y a 170k de VRAM en tout. Mais on peut s'en servir pour le code très chaud en calcul, et j'envisage de m'en servir pour des données graphiques lorsque le rendu est compliqué (eg. alpha blending). Je ne sais pas à quel point on va gagner toutefois, parce qu'il y a déjà le cache dans la partie, et il est possiblement encore plus rapide...
J'ai en tête un certain type d'affichage de jeu (à trois lettres, cough cough) que j'aimerais pouvoir faire à une fréquence raisonnable. Notamment un HUD, une map tilée en plein écran avec possiblement deux calques, des entités sur la map et quelques effets spéciaux possiblement avec alpha blending. Pour l'instant les performances ne permettent pas de jouer à ça.
Ajouté le 15/09/2019 à 14:48 :
J'ai mis le doigt sur les deux défauts de comportement qui me restaient encore à éclairer.
Autrement dit, à cause de la fragmentation du système de fichiers, il est impossible d'afficher de façon générale des images prises dans la ROM avec le DMA. Et si les images tiennent dans la RAM alors elles sont assez petites pour que ça ne vale pas la peine d'utiliser le DMA.
The SuperHyway bus master module, such as DMAC, cannot access IL memory in sleep mode.
Pris autrement, cela signifie qu'on ne peut pas endormir le processeur pendant un transfert DMA dont la source ou la destination est la mémoire IL. Ce n'est pas un problème en soi. Seulement, lors de mes tests j'attendais toujours que le transfert DMA se termine avant de rendre la main au programme pour éviter des effets tordus. Lorsque les interruptions sont activées, mon driver effectue cette attente en endormissant la calculatrice, ce qui arrête aussi la mémoire IL, et donc le transfert DMA, et donc la calculatrice ne se réveille jamais.
Avec ça, mon driver contient maintenant toutes les fonctions que j'envisageais initialement, il n'y a plus aucun bug connu, et je peux même accéder à la mémoire IL. Par contre le gain de performance est très modeste, et loin d'être satisfaisant.
Citer : Posté le 15/09/2019 19:02 | #
Dans le cas d'un affichage de VRAM, les cas tordus dont tu parles ce sont des read/write after read/write ? Dans ce cas, le seul problème qui peut avoir lieu, c'est que quelques octets de la VRAM soient corrompus, et dans ce cas on a quelques pixel qui sont pas de la bonne couleur, pour une frame uniquement.
L'intérêt que je vois du DMA, c'est justement de pouvoir paralléliser le calcul physique et de rendu avec le transfert de la VRAM. Si on attend que le DMA ait fini sa copie, je vois moins l'intérêt.
Et avec un système de flag/lock, y'a pas moyen de paralléliser ce qui est possible, puis ensuite attendre que le DMA ai fini pour relancer une copie ? Ou alors j'ai pas tout à fait compris que ce tu faisais…
Citer : Posté le 15/09/2019 19:09 | #
En effet, pour l'instant je me place dans un cadre où corrompre une partie de la VRAM n'est pas acceptable. En plus, continuer l'exécution pendant que le DMA tourne peut donner des surprises très déplaisantes comme freezer n'importe comment si tu réutilises le DMA avant que le transfert ne soit fini. Mon application de test en serait capable...
Ici, il ne s'agit pas d'utiliser le DMA pour faire le transfert à l'écran (qui marche déjà tout seul) mais carrément pour dessiner ou transférer de la mémoire. Dans ce cas, l'intérêt était que l'opération était plus rapide. Je ne parle même pas encore de paralléliser. (En effet, dans le cas VRAM → DD, paralléliser est facile car il suffit de changer de VRAM. Mais dans le cas dessin c'est moins évident.)
En tous cas, oui on peut sans problème bosser un moment selon les possibilités plus attendre le DMA plus tard. Il suffit d'appeler dma_transfer(), bosser, puis appeler dma_transfer_wait(). Actuellement je fais les deux d'un coup parce que mon add-in de test s'en fout royalement, il a déjà des perfs très larges.
Citer : Posté le 15/09/2019 19:35 | # | Fichier joint
Fichier joint
Je viens de pousser une série de commits qui ajoute dma_memcpy() et trois macros GILRAM, GXRAM et GYRAM qui permettent de placer des données dans les trois mémoires on-chip de la calculatrice, les mémoires IL, X et Y.
J'ai également construit une expérience dans gintctl permettant de mesurer la taille de ces zones ; elles font 4k, 8k et 8k respectivement.
Citer : Posté le 15/09/2019 20:25 | #
Du coup, il y a finalement un dma sur les graph monochromes ou non ?
Projet de jeu multijoueur : 1V1 3D
Une lib de debug simple : la liblog
Citer : Posté le 15/09/2019 21:33 | #
Du coup, il y a finalement un dma sur les graph monochromes ou non ?
Pour l'instant non, il n'y en a pas.
Ajouté le 28/09/2019 à 20:47 :
Je viens de pousser une mise à jour importante : l'ajout de keydown() et la finalisation du clavier.
Je m'explique. Jusque-là le fonctionnement du clavier était meh car il n'était pas compatible avec une fonction keydown(). Tout comme je raconte souvent que GetKey() et IsKeyDown() ne peuvent pas être utilisés ensemble dans fxlib, ajouter keydown() posait problème à gint : cela donnait plusieurs façons incompatibles de lire les informations du clavier.
Heureusement, ce problème est maintenant résolu ! J'ai trouvé une façon de les faire marcher ensemble. Il s'agit de synchroniser keydown() avec les événements.
Dans gint, l'information primaire sur le clavier est une file d'événements qui disent qu'une touche a été appuyée ou relâchée à un certain moment du temps. Imaginons que j'appuie puis que je relâche EXE après une seconde, ça donnera deux événements qui ressembleront à ça :
<t=13s, released EXE>
Maintenant si j'appelle pollevent() je récupérerai le premier (<t=12s, pressed EXE>). Si je recommence, j'aurai le suivant (<t=13s, released EXE>), et si je continue j'aurai un événement vide avec le temps actuel (par exemple <t=18s nothing>).
Comme vous pouvez le voir, avec ce système je dois lire les événements pour comprendre ce qui s'est passé. Tant que je n'appelle pas pollevent(), même si la touche a été pressée puis relâchée 10 fois je n'en saurai rien. Implémenter keydown() comme dans fxlib casserait ce principe. Donc à la place, je fais renvoyer à keydown() l'état de la touche selon les événements qui ont été lus. Voilà un exemple de ce qui se passerait dans le programme :
keydown(KEY_EXE) -> 0
(Je relâche EXE, le driver génère <t=13s, released EXE>.)
keydown(KEY_EXE) -> 0
pollevent() -> <t=12s, pressed EXE>
keydown(KEY_EXE) -> 1
pollevent() -> <t=13s, released EXE>
keydown(KEY_EXE) -> 0
pollevent() -> <t=18s, nothing>
keydown(KEY_EXE) -> 0
Comme vous pouvez le voir, il faut lire les événements pour que keydown() suive. C'est en fait la bonne réponse dans ce modèle, et cela permet de combiner les différentes approches. En particulier, dans un jeu, on voudra lire les événements un par un pour reconstituer tout ce que le joueur a tapé depuis le dernier frame, et au fur et à mesure de la simulation on pourra utiliser keydown() pour analyser le clavier.
Si vous voulez juste utiliser keydown() tout seul, il suffit de lire tous les événements chaque fois que vous analysez le clavier, ce pour quoi il existe une fonction raccourcie clearevents(). De plus, vous pouvez de façon fiable appelez keydown() plusieurs fois d'affilée, car même si une touche est pressée pendant que vous faites des tests, la valeur ne changera qu'une fois que vous aurez relu les événements.
Avec tout ça, je suis enfin satisfait de mon modèle clavier, et je pense que ça va rester comme ça jusqu'à la v2 et au-delà !
Citer : Posté le 28/09/2019 22:06 | #
Nyace ♥
Hâte de voir ce qu'on peut faire avec
Citer : Posté le 29/09/2019 11:37 | #
Essentiellement on peut tout faire avec !
La vraie propriété utile c'est que le clavier peut profiter de sa précision complète (128 FPS par défaut, 256 si tu veux) même si l'application n'a pas ce niveau de performance.
En particulier, si on l'utilise bien, on peut avoir un jeu qui tourne à 10 FPS graphiquement mais qui est capable de traiter des combos de façon bien plus fluide que 10 FPS. Même en un moment de lag, les événements sont enregistrés et tous les combos seront exécutés proprement une fois que le jeu retournera dans le moteur physique.
De plus, la durée mesurée des pressions sera aussi plus précise que le framerate de l'application, donc par exemple dans un jeu où l'on déplace le personnage avec les touches fléchées, on pourra avoir une meilleure fluidité. Surtout, encore une fois, si l'application lagge. Et je pense que ça se produira sur Graph 90.
Citer : Posté le 24/10/2019 14:56 | #
J'ai une question :
Est-il possible d'associer une fonction qui doit être obligatoirement exécutée à la fin d'un callback ?
Je sais qu'il est possible de forcer le programmeur à la mettre, mais existe-t-il plus raffiné ?
En fait j'aimerais qu'une fonction remette une variable dans un état particulier à la fin de l'interruption, en l'occurence se placer dans une vram particulière, sans que la personne ait à se soucier de ce détail. (ici c'est pour faire du double buffering)
Projet de jeu multijoueur : 1V1 3D
Une lib de debug simple : la liblog