[Tutoriel] Initiation à l'assembleur SuperH
Posté le 30/08/2013 20:14
Je vous présente ce petit tutoriel écrit entre la salle d'entrainement du code de la route, la salle d'attente du médecin et le train. Ne voyez pas ce tuto comme un cours complet pour savoir coder comme un pro en assembleur, pour la simple raison que je ne suis moi-même pas capable de super bien coder en assembleur. Voyez ça plutôt comme une rampe de lancement pour vous donner les bases et éviter de galérer sur des points ou j'ai moi-même galéré.
J'ai appris sur le tas en faisant mon "SH4 compatibility tool", j'ai jamais suivis de cours/tuto, donc il y a de fortes chances que je n'emploie pas les bons termes ou que je dise carrément de bêtises, ne prenez pas ce tuto pour la bible superH. La bible superH, je vais vous la présenter et elle fait 581 pages

Pour pouvoir aborder ce tutoriel, vous devez maitriser le C, très bien maitriser le concept de base numérique et en particulier bien gérer le binaire, le décimale et l'hexadécimal (l'hexadécimal que je noterais avec le préfixe 0x)
Notez que ce tutoriel porte sur l'assembleur superH, celui qui fonctionne avec les processeurs Renesas SuperH et ça n'a rien à voir avec l'assembleur x86 qu'il y a sur votre ordinateur (seuls les concepts de base restent, mais les instructions et tous les outils auxquels nous avons accès changent).
Qu'est ce qu'un programme
Vous êtes vous déjà demandé qu'est-ce que contient un fichier de programme une fois compilé et comment l'ordinateur l'exécute ce fichier ?
Le processeur d'un ordinateur (ou d'une calculatrice) est capable d'exécuter différentes instructions élémentaires. Une instruction est une très petite opération, par exemple "Copier 1 octet depuis cette mémoire vers un autre endroit en mémoire", "ajouter une valeur à une autre" ou encore "Mettre 1 dans un endroit en mémoire si une valeur est supérieure à une autre". Lorsqu'en C, vous faites un "if", il sera représenté par plusieurs instructions.
Un "exécutable" ou chez nous un AddIn est une sorte de liste de ces différentes instructions. Evidemment elles ne sont pas écrites dans un langage facilement lisible par les humains car ça n'est pas destiné aux humains et si c'était compréhensible par un humain ça prendrait beaucoup plus de place. Pour vous donner un ordre d'idées, en assembleur superH la longueur d'une instruction est constante et elle fait 16bits, c'est-à-dire deux octets (équivalant à deux caractères).
Le langage assembleur est en fait une traduction de ces instructions de sortes qu'elles soient lisible par l'homme. Enfin ça ne veut pas dire que c'est compréhensible par le premier venu.
 Les adresses et les registres
Les adresses et les registres
Les instructions que nous avons vues précédemment manipulent principalement :
- Des
adresses qui représentent selon les cas vont représenter simplement un stockage en mémoire, ou un accès pour lire et écrire sur l’écran, ou encore lire les entrées du clavier.
- Des
registres : ce sont des sortes de variable qui vont nous permettre de stocker temporairement une valeur. Ils peuvent contenir 4 octets et il en existe un nombre limité et défini par le type de processeur. Certains ont un rôle défini et ne devront pas être modifiés sans en comprendre leurs fonctionnements sous peine de faire planter la calculatrice, voire de lui causer des dégâts. Nous utiliserons très souvent les registres généraux : R0, R1, R2,…, R15, mais il en existe d'autres comme PC qui contient la position actuelle dans le fichier.
- Des
flags (drapeaux en français) : Ce sont eux aussi des sortes de variables, sauf qu'ils ne peuvent contenir que 1 ou 0. Eux aussi peuvent avoir un rôle défini et sont en nombre limité et défini par le type de processeur. Nous utiliserons souvent le flag "T" qui contient le résultat des comparaisons entre deux valeurs.
Vive les jump et les labels
Si vous connaissez le basic Casio, vous aurez peut-être entendu qu’on n’aime pas les labels/goto car ça casse le principe d'algorithmes. Ici on peut les utiliser sans se faire insulter par les puristes car c'est tout simplement le seul moyen de passer d'un endroit à un autre. C'est comme ça que fonctionne une machine, lorsqu'on appelle une fonction, il va "jumper"(sauter) au début de la fonction et à la fin il "jump" là où il était avant. Tout fonctionne comme ça. Le langage assembleur étant une sorte de traduction "mot à mot" du langage machine, vous retrouvez le même fonctionnement. C'est, entre autres, pour ça que coder en assembleur n'est pas simple et ne ressemble pas totalement à de l'algorithme à proprement parler.
Les types
Il existe trois types gérés naturellement par le processeur:
- Byte : un octet
- Word : 2 octet
- Longword : 4 octets
On les retrouvera souvent dans les noms d'instructions avec leurs initiales. Par exemple il existe MOV.B, MOV.W et MOV.L.
La première lecture d'un code assembleur
Comme première application de ce que nous avons vu précédemment, nous allons :
- Compiler une fonction en C
- Récupérer le binaire
- Le désassembler manuellement (c'est-à-dire le traduire en langage assembleur)
- En comprendre le fonctionnement.
Compiler une fonction en C
Créez un nouveau projet sur le SDK Casio et en dessous des #incude, vous collez simplement le code suivant, sans chercher à appeler cette fonction quelque part, elle ne sera jamais exécutée et ce n’est pas un problème.
int test()
{
int bob;
bob = 9;
bob++;
return bob;
}
Comme vous le voyez ce code n'a strictement aucun intérêt, mais ce n'est pas grave, le compilateur va quand même le traduire en langage assembleur et c'est ce que l'on veut.
Récupérer le binaire
Nous allons récupérer le contenu de cette fonction sous forme hexadécimale. Pour cela, il va vous falloir un éditeur hexadécimal. C'est-à-dire un éditeur comme Notepad, à la différence qu'il va y avoir une colonne où chaque octet est représenté sous forme hexadécimal et sur la droite vous aurez une deuxième colonne qui vous affiche la traduction de ces octets en caractères afin de repérer des textes s'il y en a, mais cette colonne ne nous sera pas vraiment utile pour l'instant.
Le meilleur éditeur hexadécimal que je connaisse (et croyez-moi, j'en ai testé pas mal) est
HxD (
ici pour télécharger ) même s'il a toujours quelques défaut comme le fait d'être incompatible sur linux (désolés pour les linuxiens ou les macintoshiens, je vous laisse faire une petite recherche sur Google pour trouver votre bonheur, vous en trouverez forcément. Le problème est d'en trouver un bien). Et puis sinon, Wine
Vous allez donc ouvrir le fichier g1a que vous venez de compiler avec votre éditeur hexadécimal. Vous verrez qu'à première vue ce n'est pas très accueillant et que ça risque de ne pas être simple de retrouver notre fonction la dedans.
Heureusement, notre compilateur génère un fichier très pratique lorsqu'il compile : allez dans le dossier de votre projet, puis dans le dossier "Debug" et ouvrez avec Notepad (ou Notepad++, comme vous voulez) le fichier "FXADDINror.map". Ce fichier contient, entre autres, la liste des fonctions de votre programme ainsi que leurs adresses. (Vous verrez qu'il y a aussi pleins de fonctions qui ne vous concernent pas car elles viennent de la fxLib). Voici la partie qui nous intéresse :
_test
0030020c 8 func ,g *
Nous savons donc que l'adresse de cette fonction dans la mémoire de la calculatrice est 0x0030020c et qu'elle a une longueur de 0x8 octets. Or lorsqu'un fichier est chargé dans la mémoire de la calculatrice, il le charge à l'adresse 0x00300000. Ce qui veut dire que l'adresse de notre fonction dans le fichier est en fait 0x30020c-0x300000 = 0x20c.
Donc maintenant le but est de trouver l'octet ayant pour offset (position) 0x20c. Donc sur la colonne tout à gauche de votre éditeur vous verrez une liste de nombre allant de 0x10 en 0x10, vous devez donc trouvez la ligne 0x200. Puis une fois que c'est fait vous recherchez dans cette ligne, la colonne qui a pour en-tête 0xc et vous aurez normalement trouvé l'offset 0x20c. Vous sélectionnez 8 octets à partir de celui-là et vous aurez le contenu de notre fonction.

Et vous obtenez donc cette liste d'octets
E4 09 74 01 00 0B 60 43Ouais, mais je vous ai déjà dit qu'une instruction prenais 2 octets, donc on peut les regrouper par instructions:
E409
7401
000B
6043
Remarquez qu'il y a 4 instructions.
Désassembler et trouver la signification de chaque instruction
Je vais vous présenter un document PDF qui contient tout ce qu'il y a à savoir sur notre processeur. Nous prendrons celui des SH3 (car les SH4 pour casio ont les mêmes instructions que les SH3 alors qu'à la base ils en ont plus et si vous prenez celui des SH4, vous aurez donc des instructions en trop si vous prenez celui des SH4).
Renesas SH-3/SH-3E/SH3-DSP Software Manual ou "The fucking manual" (notez que tout ce qui concerne SH-3E et SH3-DSP ne nous concerne pas).
Si vous l'ouvrez, vous risquez d'être un peu perdu tellement le machin est gigantesque (581 pages). Je vous rassure on va ne pas tout lire
Normalement vous devriez avoir une table des matières qui devrait s'afficher quelque part dans votre logiciel. Si vous la voyez pas, essayer de trouver un réglage qui l'affiche ou essayez d'utiliser Foxit Reader, c'est ce que j'utilise car il est plus rapide que celui d'adobe et il affiche par défaut cette table.
Dans la doc, les instructions sont représentées en binaire, donc on va traduire nos instructions pour que ce soit plus simple de les reconnaitre. (Utilisez la calculatrice windows en mode programmeur si vous ne savez pas le faire ou que vous avez la flème)
1110 0100 0000 1001
0111 0100 0000 0001
0000 0000 0000 1011
0110 0000 0100 0011
Allez dans "Section 7 Instruction Set" > "7.2 Instruction Set in Alphabetical Order" (milieu de la page 113).
Vous allez trouver un gros tableau avec à chaque ligne un code en binaire (avec les parties variables remplacés par des lettres).
Comparez les 4 premiers bits (on appelle ça un nibble) c'est à dire dans notre cas 1110 de chaque lignes. Puis si vous en trouvez un qui correspond, vous vérifiez si la suite correspond.
Les parties remplacées par des lettres peuvent avoir n'importe quel contenu.
Notez qu'il peut y avoir aucune instruction correspondante dans certains cas.
Aide
Banane !
Vers la fin de la page 118
Réponse pour la première ligne : 1110 0100 0000 1001
Patate !
MOV #imm,Rn [courier]1110nnnniiiiiiii[/courier]
Donc on a trouvé l'instruction en question, maintenant on va reconstituer les paramètres :
nnnn correspond à 0100=0x4 donc n=4
iiiiiiii correspond à 00001001=0x9 donc imm=9Et donc notre instruction complète est
MOV #9,R4Même sans trop de connaissances, et sachant que R4 est un registre, on peut deviner que cet instruction met la valeur 9 dans le registre r4.
Notez que vous pouvez rencontrer cette instruction sous cette forme :
MOV #h'9,R4
Car h'n veux dire que n est en notation hexadécimal (équivalent de 0x) sauf qu'ici 9=0x9=h'9 donc ça change rien.
Vous vous posez peut-être la question à quoi correspondent ces nnnn, dddd, iiii ou mmmm :
-
nnnn, mmmm sont des numéros de registres généraux (r0 à r15). Leurs valeurs doivent remplacer respectivement "n" et "m" dans l'instruction donnée dans la doc.
-
iiii (ou
iiiiiiii, iiiiiiiiiiiii) contient une valeur immédiate, c'est à dire une valeur contenu directement dans l'instruction. Cette valeur remplacera "imm" dans l'instruction donnée dans la doc.
-
dddd (ou
dddddddd, ddddddddddddd) contient une "déplacement" (displacement), c'est à dire une valeur qu'on va ajouter à une adresse (généralement contenu dans un registre) afin d'atteindre un point précis. Cette valeur remplacera "disp" dans l'instruction donnée dans la doc.
Réponse pour la deuxieme ligne : 0111 0100 0000 0001
Patate^2
ADD #imm,Rn [courier]0111nnnniiiiiiii[/courier]
Reconstituons les paramètres :
[courier]nnnn [/courier]correspond à 0100=0x4 donc n=4
[courier]iiiiiiii [/courier]correspond à 0000001=0x1 donc imm=1
et donc notre instruction complète est
ADD #1,R4
Encore une fois ça me semble pas trop difficile à comprendre : On ajoute "1" au registre r4
Réponse pour la troisième ligne : 0000 0000 0000 1011
Patate^3
RTS
0000000000001011
Cette fois-ci il n'y a pas de paramètres. Et si je vous demande à quoi sert cette instruction, je ne pense pas que vous trouverez. A moins qu'on utilise la documention pour qu'elle nous donne une description.
Pour mieux comprendre ce que fait l'instruction RTS, vous allez aller dans ces chapitres :
"Section 8 Instruction Descriptions" > "8.2 Instruction Description (Listing and Description of Instructions
Common to the SH-3, SH-3E and SH3-DSP)"
puis trouvez votre instruction.
TFM a écrit :
Returns from a subroutine procedure.
On apprend donc que cette instruction sert à revenir d'une "subroutine"(sous-routine en français.. oui, je sais ça aide pas). En C on appellerais cette sous-routine "une fonction" tout simplement. Donc en gros, il appelle ça à la fin d'une fonction pour revenir là où il était avant de commencer la fonction.
La bible en version numérique a écrit :
The PC values are restored from the PR, and
the program continues from the address specified by the restored PC value. This instruction is used
to return to the program from a subroutine program called by a BSR or JSR instruction.
Là on entre dans les détails techniques de cette instruction. Donc le registre PR est copié dans le registre PC (je rappelle que PC contient l'adresse d'exécution actuelle. Donc si on modifie le registre PC, le programme ira continuer à l’endroit indiqué). En fait le registre PR est utilisé pour stocker l'adresse d'où est partie la fonction, vous n'êtes pas censé l'utiliser pour autre chose (même si c'est techniquement possible).
Cornichon a écrit :
Note: Since this is a delayed branch instruction, the instruction after this RTS is executed before branching.
Branching = jumper dans une subroutine
On apprend donc que c'est une "delayed branche instruction" et que pour cette raison, l'instruction placé juste après sera exécuté avant de jumper. Vous devez donc faire attention à ce qu'il y a juste après. Vous trouvez peut-être cela bizarre, c'est en fait du à la façon qu'a le processeur de gérer les instructions, ce n'est pas vraiment un choix qui est utile pour nous. Mais en même temps un programme n'est pas fait pour être compréhensible par vous, mais par la machine.
Sous cette description vous trouverez an algorithme en C qui représente ce que fait cette instruction. Pratique pour ceux qui comprennent pas l'anglais de la doc (qui peut, je vous le concède, être assez difficile quand on ne connait pas beaucoup de choses sur le processeur ou en assembleur)
PC=PR+4;
Je vous ai un peu mentit tout à l'heure, PC ne contient pas l'addresse actuelle, mais
l'addresse actuelle + 4. Donc ici on copie bien PR dans PC.
temp=PC;
Delay_Slot(temp+2);
Si vous regardez plus haut dans la doc vous verrez que cette fonction Delay_Slot permet d'executer une autre instruction avant de "sauter" vers un autre endroit. Ici on execute donc l'instruction PC+2 qui correspond bien à la ligne du dessous (une instruction fait deux octets donc PC+2 est l'instruction du dessous)
Réponse pour la quatrième ligne : 0110 0000 0100 0011
Patate^4
MOV Rm,Rn [courier]0110nnnnmmmm0011[/courier]
Instruction complète :
Mov r4,r0
Cette instruction est facile à comprendre sachant qu'on a déjà vu son amie.
Bon et bien on a réussi à désassembler chaque instruction, donc si on récapitule tout ça nous donne
MOV #9,R4 ; On met 9 dans le registre r4
ADD #1,R4 ; On ajoute 1 à r4
RTS ; On retourne de la fonction
Mov r4,r0 ; Mais avant on copie r4 dans r0
(En assembleur, les commentaires sont après le ";" et il n'est pas nécéssaire de mettre des ; à la fin des lignes sauf dans le cas ou vous commentez bien evidement)
Si on compare à notre code en C, ça ressemble assez, on fait une variable qui vaut 9 et on lui ajoute 1.
En voyant ça, je sais pas vous, mais mois je me pose plusieurs questions :
-
Pourqoi à la fin pourquoi il copie r4 dans r0 ?
Par convention, on fait en sorte que r0 contienne la valeur de retour de votre fonction. Ce qui permet de la récuperer après assez facilement.
-
Pourquoi au lieu de faire
MOV #9,R4
ADD #1,R4
Il ne fait pas directement
Mov #10,r4
Là, la réponse est simple, le compilateur n'a juste pas optimisé notre code C. Donc en fait ici c'est plutôt de notre faute. Le compilateur fait certaines optimisations, mais il n'est pas meilleur que l'homme dans ce domaine (en principe).
-
Pourquoi au lieu de faire
MOV #9,R4
ADD #1,R4
RTS
Mov r4,r0
Il ne fait pas directement
MOV #9,R0
RTS
ADD #1,R0
Cette fois-ci ce n'est pas de notre faute, le compilateur n'a pas optimisé, et en C on ne peut rien y faire. Cependant une fois que vous connaissez l'assembleur vous pouvez optimiser vous-même certaines fonctions qui sont très utilisé dans votre code et qui ont besoin d'être rapide.
Donc la fonction la plus optimisée aurait été
RTS
MOV #10,R0
Et on a divisé la taille (et en principe la durée) de cette fonction par 2.
Quand on est feignant
Ou quand un fichier binaire est très long, on ne va pas s'amuser à tout désassembler à la main. On utilise donc le désassembleur. Je vais vous en présenter deux :
-
SuperH3 disassembler : C'est un simple désassembleur. Il suffit d'y glisser votre fichier binaire et il vous ressortira un fichier texte avec la liste des instructions. L'avantage est que c'est très rapide à utiliser et qu'il traite sans problème n'importe quel fichier binaire. L'inconvénient majeur est que contrairement au désassembleur suivant, on ne peut pas exécuter le code étape par étape et voir ce qui ce passe.
Si vous voulez le tester, vous téléchargez le fichier. Vous décompressez dans un dossier puis glissez votre g1a sur l'exécutable. Si tout se passe bien vous verrez la console s'afficher en éclaire et un fichier output.txt apparaitra dans le même dossier. Vous l'ouvrez et allez à l'offset 0x0020c (les offsets sont la colonne de gauche). Vous verrez normalement le code qu'on a désassemblé précédemment.
-
Casio fx-9860G SDK : En principe vous le connaissez bien celui-là, sauf que vous ne l'avez sans doute jamais utilisé comme désassembleur. Mais avant de l'utiliser, on va modifier un tout petit peu notre code. Vous allez mettre appeler test(); en haut de la fonction AddIn_main, juste après les déclarations de variable afin que l'émulateur exécute notre fonction test().
Ensuite vous allez aller dans le menu "view" puis ouvrez les sous-fenêtres "Disassembled code", "Registers". Bon la fenêtre "Disassembled code" ne contient pas grand-chose pour l'instant, on peut par contre déjà parler de la fenêtre "Registers". Vous vous en doutez, elle contient l'état actuel des registres; vous retrouvez donc nos r1 à r15, d'autres registres qui ont un rôle définie (je vous laisse lire la doc pour savoir à quoi ils servent), et dans la dernière ligne vous pouvez trouver les flags, dont notre fameux flag T. Pour info, à chaque fois qu'un registre est modifié dans cette fenêtre, la ligne du registre sera écrite en rouge lorsque la valeur est réellement modifiée, et elle sera en vert lorsqu'elle est la même qu'avant (dans le cas où vous écrivez 0 et qu'il y avait 0 avant par exemple).
Maintenant qu'on a préparé l'interface, vous allez lancer l'émulateur comme d'habitude, lancez aussi votre programme. Vous verrez normalement le fameux "This application is sample add-in" sur l'écran, et vous allez cliquer sur stop (le carré bleu à côté de celui qui lance l'émulateur). Vous allez ensuite aller sur la fenêtre "Disassembled code". Faites clic droit sur une des lignes (peu importe laquelle) puis cliquez sur "goto...". Ce menu nous permet de nous déplacer rapidement à un autre endroit de la mémoire. Nous, nous voulons voir notre fonction test, on va donc écrire dans la fenêtre qui apparait 30020c. Vous vous retrouvez normalement bien sur la bonne ligne et vous devriez retrouver le code que nous avons désassemblé.
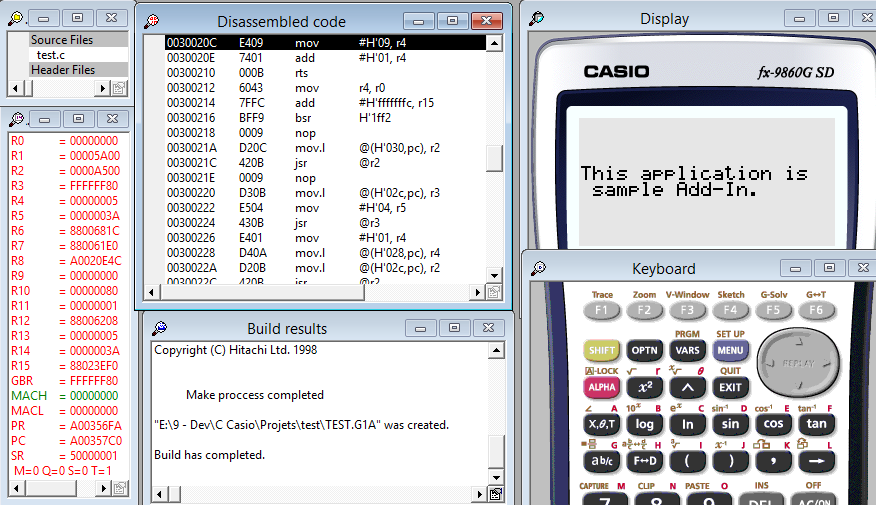
C'est bien beau d'avoir le code désassemblé, mais si on l'utilise c'est pour voir la situation évoluer pas à pas, il faut donc qu'on se débrouille pour que l'émulateur s'arrête pile poil au début de la fonction. On va donc utiliser un breakpoint à l'adresse de début de notre fonction. Un braekpoint est une adresse où on ordonne à l'émulateur de s'arrêter lorsqu'il y accède tout simplement. Pour cela vous faites clic droit sur la ligne 30020c et "Set breakpoint".
Maintenant pour il faut relancer l'émulateur car au point où nous en somme votre fonction a déjà été exécuté. Pour relancer l'émulateur, à ce que je sache, si on ne veut pas recompiler notre AddIn, il faut cliquer sur "reload project" (le bouton à gauche de la compilation). Vous relancez ensuite l'émulateur et votre programme, et si tout se passe bien l'émulateur devrait s'arrêter et vous montrer la fenêtre du code désassemblé, avec notre ligne 30020c comportant le rond rouge signifiant qu'il y a un break point et une flèche jaune signifiant que l'émulateur est actuellement sur cette ligne.
Ensuite normalement si vous cliquez sur "trace into" il est censé passer à l'instruction suivante. Vous testerez vous mêmes, mais personnellement lorsque le code est de base en C, l'émulateur a tendance à ne pas vouloir faire du "pas à pas" et à sauter pas mal de lignes, mais parfois ça fonctionne. Le seul moyen que j'ai trouvé c'est de mettre des breakpoints à chaque lignes. C'est chiant, mais on ne peut pas vraiment faire autrement.
Donc si il saute trop de ligne (notamment s'il ne vous montre pas la ligne "mov r4,r0", c'est ce qui se passe chez moi). Cliquez sur le bouton "reload project" relancez l'émulateur et lorsqu'il a atteint notre fonction placez des breakpoint à chaque ligne.
En principe lorsqu'il aura passé la première ligne vous verrez dans la liste des registre, le r4 qui sera en rouge et vaudra 9, si vous faites la ligne suivant il vaudra 10 (enfin 0xA), bref comme on avait prévu. (Vous verrez aussi la ligne PC qui sera en rouge car l'adresse actuelle a changé)
Notez que la ligne actuellement surligné dans le code désassemblé est celle qui sera exécuté juste après. Vous pouvez voir aussi que l'émulateur n'a pas l'aire de respecter le fait que le registre PC est la ligne actuelle + 4. Lui il fait juste la ligne actuelle, me demandez pas pourquoi, peut-être pour nous embrouiller, comme l'histoire du "trace into" qui bug ?
La stack
Vous vous êtes peut-être poser la question de ce qu'il se passe lorsqu'on a besoin de plus de registres, ou alors lorsqu'on appelle une fonction dans une fonction (le registre pr contient déjà l'adresse de la suite de la première fonction et donc si on va dans une autre fonction ce registre sera effacé et ça changera tout)
Dans la mémoire, une partie est réservé à contenir la stack. Stack veut dire pile, donc comme son nom l'indique, on va empiler les données dans cette mémoire. Et généralement on va y envoyer des infos, dans un ordre puis les retirer dans le sens inverse. On peut comparer ça à une pile de livre. Lorsque vous en poser un vous recouvrez celui de dessous, mais si vous voulez récupérer celui du dessous, il sera plus simple de retirer le premier livre.
Une utilisation assez courante de la stack est au début et à la fin d'une fonction. Si votre fonction a besoin du registre r10, r11 et r12 par exemple. Ces registres doivent avoir la même valeur au début et à la fin de la fonction. Pour cela on utiliser cette structure :
r10 -> stack
r11 -> stack
r12 -> stack
//Votre code
stack -> r12
stack -> r11
stack -> r10
Ainsi dans votre code vous pouvez utiliser les registres r10,r11 et r12 sans problème. Vous pouvez faire de même pour le regstre PR afin de pouvoir utiliser une fonction dans une fonction.
Donc cette pile se situe à un certain endroit en mémoire. Et pour savoir où nous en sommes dans la pile nous devons avoir accès a une valeur qui sera toujours disponible et qui contiendra l'adresse du haut de cette pile. C'est à dire l'adresse du dernier endroit réservé. Ici la pile marche un peu à l'envers car on va commencer par l'adresse la plus élevé de la pile, puis lorsqu'on reserve une case de la pile, on va soustraire le nombre d'octet que l'on réserve à l'adresse. Je ne suis pas sûr que ce soit très clair pour vous, donc je vais juste vous préciser que cette fameuse adresse est stockée en r15 avant de passer à un exemple.
Donc on traduirait le code précédent comme ça en assembleur
add #-4,r15 ; On reserve 4 octet car un regsitre fait 4 octet
mov.l r10,@r15 ; On envoi r10 dans l'addresse qu'on lui a reservé
; (le @ indique donc qu'on déplace r10 vers l'addresse pointé par r15 et non vers r15)
add #-4,r15 ;On recommance pour les autres
mov.l r11,@r15
add #-4,r15
mov.l r12,@r15
; votre code
mov.l @r15,r12
add #4,r15
mov.l @r15,r11
add #4,r15
mov.l @r15,r10
add #4,r15
Vous pouvez vous dire que c'est un peu répétif, et c'est pour ça qu'il existe une instruction qui permettre d'enlever les "add"
mov.l r10,@-r15 ; Ici il soustrait 4 avant de copier r10 vers @r15
mov.l r11,@-r15
mov.l r12,@-r15
; votre code
mov.l @r15+,r12 ; ici il ajoute 4 après de copier
mov.l @r15+,r11
mov.l @r15+,r10
Les conventions
En assembleur, si on en a envie, on peut faire n'importe quoi, rien n'est vraiment bloqué. Par exemple si vous voulez utiliser le registre PR ou r15 pour stocker des données, c'est possible le compilateur ne vous dira rien, mais vous faites une grosse erreur. Des conventions ont été mis en place afin que les programmes/fonctions s'entendent entre eux.
Comme nous l'avons vu, Casio a mis en place la convention que le registre r15 contient l'adresse actuelle de la stack. Renesas (les fabricants du processeur) ont mis en places d’autres registres réservés : tout ceux dont le nom n'est pas r0 à r15.
Donc pour l'instant, d'après ce que nous savons, nous pouvons modifier les registres r0 à r14 sans problème. En fait non. Les registres r0 à r7 peuvent être modifié sans modération ni sauvegarde. Les registres r8 à r14 doivent être sauvés comme nous l'avons vu dans le chapitre précédent avant de les modifier.
source
Il existe d'autres conventions, notamment celles nous permettant d'appeler une subroutine. Avant d'appeler une subroutine, vous devez stocker les paramètres de cette subroutine dans r4, r5, r6 et r7.C'est à dire que lorsque vous faites
fonction(1,2,3,4,5)le 1 est stocké dans r4, le 2 dans r5, 3 dans r6 et 4 dans r7. Quant au 5 (ainsi que tout autre paramètres supplémentaires), il sera stocké dans la stack (je n'ai pas vraiment toucher à des fonctions de plus de 4 paramètres donc si vous voulez en savoir plus sur les paramètres en stack, faites un code en C et observez le pour mieux comprendre). A la fin d'une subroutine, la valeur de retour est stockée dans le registre r0.
L'alignement mémoire
Pour les opérations sur 4 octets comme MOV.L, il existe une subtilité qu'il faut bien noter : elle ne peut modifier ou accéder qu’à une adresse étant un multiple de 4. Il en va de même pour MOV.W qui ne peut accéder/modifier que des adresse étant multiple de 2.
En principe, il suffit de le savoir et de bien faire attention pour ne pas faire d'erreur. Il y a cependant un cas où vous pourrez avoir quelques problèmes. Lorsque vous stockez une variable en stack. Si vous voulez stocker un byte ou un Word, vous allez sans doute vouloir utiliser
mov.b r0,@-r15 ; soustrait 1 à r15 est stocke r0 dans @r15
ou
mov.w r0,@-r15; soustrait 2 à r15 est stocke r0 dans @r15
Mais si plus loin, que ce soit dans votre code, ou dans une autre fonction, cette instruction est utilisée
mov.L r0,@-r15
r15 ne sera plus un multiple de 4, et votre addin va planter.
Vous me direz sans doute que dans ce cas, il suffit que r15 soit un multiple de 4 avant d'appeler une fonction ou avant de retourner de la vôtre ? Et bien en fait non c'est pire. Vous savez peut-être qu'il existe des interruptions : c'est à dire des morceaux de codes qui seront exécutés à différents moments en plein milieu du votre sans vous demander votre avis. Et bien si une interruption s'exécute en plein milieu de votre fonction et que r15 n'est pas un multiple de 4, votre AddIn plantera. (Merci à SimonLothar pour son explication, j'ai galéré la dessus) Donc dans tous les cas, peu importe le moment
r15 doit toujours être un multiple de 4
Vous allez sans doute penser qu'on est donc obligé de stocker que des longword en stack, ce qui n'est pas le cas, on peut très bien stocker d'autres types, il faut juste réfléchir un peu plus.
Vous ne pouvez donc pas faire ça
mov.w r4,@-r15 ; ici, r15 n'est plus un multiple de 4
mov.b r5,@-r15 ; r15 est maintenant un nombre impaire
mov.b r6,@-r15 ; ici, c'est bon r15 est un multiple de 4
Mais vous pouvez faire ça :
shll2 r4 ; on décale r4 de deux octets sur la gauche (equivalent en C de r4=r4<<2)
shll r5,r5 ; decale r5 d'un octet sur la gauche
add r5,r4
add r6,r4 ; On ajoute les trois valeurs (qui seront donc tous placés dans leurs octets respectifs automatiquemnt)
mov.b r4,@-r15 ; et on sauvegarde
On aurait aussi pus faire
add #-4,r15 ; on reserve nos 4 octets
mov r4,r0
mov.w r0,@(2,r15) ; on met r0 dans r15+2 (on ne peut pas utiliser directement r4 ici : cf la bible)
mov r5,r0
mov.w r0,@(1,r15)
mov.w r6,@r15
et voilà, et dans ces deux derniers cas r15 a toujours été un multiple de 4. On peut sans doute trouver d'autres solutions plus ou moins optimisées en fonction de situations, mais je vous laisse vous creuser la tête pour ça.
Annexe vocabulaire
Sign-extended
Description des fonction MOV à données imédiate page 216 a écrit :
Description: Stores immediate data, which has been sign-extended to a longword, into general
En informatique, un octet négatif est représenté par un nombre superieur ou égale à 0x80. (si c'était deux octet ça serait 0x8000). Par exemple
0 = 0x00
1 = 0x01
126 = 0x7e
127 = 0x7f
128 : impossible
-- negatifs --
-1 = 0xff
-2 = 0xfe
-126 = 0x82
-127 = 0x81
-128 = 0x80
-129 : impossible
Or si le conteneur est un longword (4octets) :
0 = 0x00000000
1 = 0x00000001
126 = 0x0000007e
127 = 0x0000007f
128 : 0x00000080
-- negatifs --
-1 = 0xffffffff
-2 = 0xfffffffe
-126 = 0xffffff82
-127 = 0xffffff81
-128 = 0xffffff80
-129 = 0xffffff7f
Maintenant immaginez qu'on copie la valeur -128 d'un byte vers un longword sans faire attention au signe on obtient
en byte -128=0x80
en longword 0x00000080=128
Vous venez de changer la valeur réelle car vous n'avez pas fait attention au signe.
"sign-extended to a longword" : Veut donc dire qu'il fait attention à ce que si la valeur est supérieure ou égale à 0x80, il complète avec des 0xFF sinon avec des 0x00.
General
Description des fonction MOV à données imédiate page 216 a écrit :
Description: Stores immediate data, which has been sign-extended to a longword, into general
"general" est ici l'abréviation de "General register", ou Registre géréral. Il en existe 16 : r0 à r15. (les autres ne sont pas des registres généraux)
 Fichier joint
Fichier joint

{kind=link}
Citer : Posté le 09/06/2018 18:43 | #
Alors, concernant le fait que tu as cassé ton projet, un coup de Rebuild All et suppression du dossier Debug aideront sûrement.
J'ai déjà essayé mais aucun résultats :/ (pas grave je vais refaire un projet
Comme je l'ai déjà mentionné, mov.b ne déplace qu'un octet @r6 vers r2. Or r2 contient 4 octets ; les 3 autres ne sont pas modifiés. Tu t'exposes au risque que les trois octets de r2 contiennent autre chose que des 0, et cela peut fausser ton test.
Je me base sur des bouts e code que j'ai désassembler pour comprendre la logique.
D'abord, tu es sûr sûr sûr que ton tableau test[] est un tableau de char et pas d'int ?
pour sûr:
char* wall[15];
wall_move(wall);
Ensuite, quand tu fais un mov.b ou un mov.w avec l'intention de comparer la valeur ou de faire des calculs dessus, prend le temps de nettoyer les octets supérieurs. Pour cela, tu utilises ext, qui vient en quatre variantes : exts et extu pour dire si la valeur que tu manipules est signée (s) ou pas (u), chacune avec le suffixe .b ou .w selon si tu viens d'utiliser mov.b ou mov.w.
c'est notée
(ou alors je fais mov #0, rX avant d'utiliser mov.b ou mov.w (?)).
C'est bra dont tu as besoin ici. bsr c'est pour faire un appel de fonction !
J'ai vraiment du mal avec la doc x) merci beaucoup
Citer : Posté le 09/06/2018 18:52 | #
pour sûr:
char* wall[15];
wall_move(wall);
Aha ha oui mais non. Depuis quand un pointeur ça tient dans un octet ?
Ça marche aussi, mais si la valeur est non signée alors ça ne donnera pas le même résultat. Par exemple si @r6 = 0xff (soit -1) :
mov #0, r2; mov.b @r6, r2 → r2 = 0x000000ff = 255
mov.b @r6, r2; exts.b r2, r2 → r2 = 0xffffffff = -1
Citer : Posté le 09/06/2018 19:12 | #
pour sûr:
wall_move(wall);
Aha ha oui mais non. Depuis quand un pointeur ça tient dans un octet ?
Donc si je veux déplacer r4...qui contient donc l'adresse de wall[0]... je peux le mettre que dans r8~r13 ?
en fait je vais te dire ce que j'ai compris des registres r0~r15:
r0 - c'est la valeur qui va être renvoyé par la fonction (si elle retourne quelque chose). taille: ??octets
r1~r3 - buffer (on met un peu ce qu'on met dedans). taille: 2 octets.
r4~r7: argument de la fonction. taille: 4 octets (??)
r8~r13: sert de registre permanent (aucune idée de leur utiliser). taille: ??octets
r14: "Default frame pointer" (aucune idée se sont utilisé). taille ??octets (4 je pense)
r15: address stack (lui il me fait peur, si j'ai bien pigé (visiblement pas trop) c'est ce registre qui dit ce qui/quoi doit être exécuté dans ce cycle). taille ??octets (4 je pense)
J'ai pas trop dit de bêtises ?
Citer : Posté le 09/06/2018 19:45 | #
Hein ? Quoi ? r0 .. r3 font deux octets ?
Tu sais, si le processeur est dit 32-bits c'est pas parce qu'il a un registre 32-bits mais bien parce que tous ses registres sont de 32 bits. r0 .. r15, pc, gbr, sr, tous font 32 bits. Pas moyen de se planter !
Conventions d'appels :
- r0 : contient la valeur de retour
- r4 .. r7 : premiers arguments, les autres sont sur la pile
- Une fonction appelée peut faire ce qu'elle veut avec r0 .. r7, sans préavis
- r14 : rien de particulier, c'est GCC qui s'amuse avec, pour toi c'est comme r8 .. r13
- Une fonction appelée doit restaurer les valeurs de r8 .. r15 avant de quitter
- r15 : pointeur de pile, là où on met sauvegarde les registres et où on met des variables locales
Tous font 4 octets. Tous !
Citer : Posté le 11/06/2018 12:56 | #
N'était-ce pas indiqué dans le topic de Ziqumu ?
Des registres : ce sont des sortes de variable qui vont nous permettre de stocker temporairement une valeur. Ils peuvent contenir 4 octets
Citer : Posté le 11/06/2018 13:49 | #
mmmm... bon ça fait pas mal de temps que je ne comprends pas pourquoi ça plante:
_ini_wall:
mov #0, r0 ;i=0
mov #255, r1 ;r1 = 255
mov r4, r6 ;met addresse wall (r4) dans r6
for_1:
mov.b r1,@r6
add #1, r0
cmp/eq #5, r0
bf/s for_1 ;if t==0 -> goto for_1
add #3, r6 ;delay slot: wall + 3
rts
nop
dans le fichier c:
char* wall[15];
ini_wall(wall+1);
Le problème c'est que l'add-in plante et j'arrive vraiment pas à comprendre pourquoi....
N'était-ce pas indiqué dans le topic de Ziqumu ?
C'est pas faux
EDIT: je viens de piger que chaque adresse se trouve à: adr + 0x04
Mais ça ne résout pas mon problème, 'fin si, l'add-in ne plante plus mais le programme fait pas ce que je veux et je ne comprends encore moins
Citer : Posté le 11/06/2018 15:22 | #
Aha quelle innocence.
Je te laisse lire la doc et voir pourquoi r1 = -1.
Tu as conscience que chaque élément de wall fait 4 octets, hein ? La première de ces deux lignes écrit un seul octet parmi les quatres. Quant à la deuxième, tu n'as aucune raison de vouloir faire ça. Incrémenter de trois octets te fait avancer dans le tableau de trois quarts d'un élément... pas terrible hein ?
Petit rappel :
x++; /* L'adresse x augmente de 1 octet */
short *x;
x++; /* L'adresse x augmente de 2 octets */
int *x;
x++; /* L'adresse x augmente de 4 octets */
Je vois ton edit maintenant, mais il faut que ce soit absolument clair pour toi, sans un instant de doute.
Pourquoi ton programme crashe, je n'en suis pas sûr. Aucune chance que ça soit après ?
Citer : Posté le 11/06/2018 16:04 | #
Ce que je comprends pas ce que j'ai fait ini_wall(wall); SAUF que wall c'est un char* wall[15] donc ce n'est pas censé être des chars dedans ? soit 1 octet
Je te laisse lire la doc et voir pourquoi r1 = -1.
Je m'en suis déjà rendu compte
Incrémenter de trois octets te fait avancer dans le tableau de trois quarts d'un élément... pas terrible hein ?
Bah en fait ça se tient si tu prends en compte que je suis débile, comme je pensais que c'était 1 octet par 1 octet j'ai fait add #3, r6 car je veux simplement accéder aux valeurs toutes les 3 valeurs...mais oui du coup ce n'est pas terrible x)
Pourquoi ton programme crashe, je n'en suis pas sûr. Aucune chance que ça soit après ?
J'ai régler ce problème
Citer : Posté le 11/06/2018 16:11 | #
Tu penses que c'est quoi char* wall[15] au juste ? C'est un tableau de 15 pointeurs vers char. Son type est donc (plus ou moins) char **. Si tu veux un tableau de 15 char, c'est possible, mais c'est char wall[15] dans ce cas-là.
Dans ce cas écris #-1 ou #0xff pour que le rendre visible.
Citer : Posté le 11/06/2018 16:17 | #
Tu penses que c'est quoi char* wall[15] au juste ? C'est un tableau de 15 pointeurs vers char. Son type est donc (plus ou moins) char **. Si tu veux un tableau de 15 char, c'est possible, mais c'est char wall[15] dans ce cas-là.
Houlaaaaaaa mais je suis fatigué dit donc en ce moment entre les oraux, les écrits, le bac...
C'est pour ça que je comprends pas mes erreurs... merci beaucoup <3 x)
(désoler d’être un boulet à ce point et de te déranger toutes les deux secondes
Citer : Posté le 11/06/2018 17:28 | #
Ne t'inquiète pas, c'est toujours un plaisir xD
Citer : Posté le 12/06/2018 20:21 | #
Bon mon code avance et j'ai réussi à régler tous mes problèmes
SAUF que maintenant j’aimerai utiliser la fonction rand()
J'ai donc fait ça:
/*ya du code avant*/
;call rand()
add #2, r6
mov.b r0, @r6
mov.l r6, @-r15
mov.l r5, @-r15
sts.l pr, @-r15
mov.l extern_function+2, r11
jsr @r11
nop
lds.l @r15+, pr
mov.l @r15+, r5
mov.l @r15+, r6
mov.l r0, r3
mov.b @r6, r0
/*ya du code apres*/
extern_function:
.data.w 0
.data.l _rand
quand je compile j'ai ça:
xecuting Hitachi SH C/C++ Compiler/Assembler phase
set SHC_INC=C:\Program Files\CASIO\fx-9860G SDK\OS\SH\include
set PATH=C:\Program Files\CASIO\fx-9860G SDK\OS\SH\bin
set SHC_LIB=C:\Program Files\CASIO\fx-9860G SDK\OS\SH\bin
set SHC_TMP=C:\Users\BG\Documents\CASIO\fx-9860G SDK\FLAPFLAP\Debug
"C:\Program Files\CASIO\fx-9860G SDK\OS\SH\bin\asmsh.exe" -subcommand=C:\Users\BG\AppData\Local\Temp\hmk2BF6.tmp
C:\Users\BG\Documents\CASIO\fx-9860G SDK\FLAPFLAP\asm.src(227) : 200 (E) UNDEFINED SYMBOL REFERENCE
*****TOTAL ERRORS 1
*****TOTAL WARNINGS 0
HMAKE MAKE UTILITY Ver. 1.1
Copyright (C) Hitachi Micro Systems Europe Ltd. 1998
Copyright (C) Hitachi Ltd. 1998
ERROR: Process failed with return code: 2
Build was not successful.
Du coup je sais pas trop comment faire je sais que l'erreur signifie "je trouve pas rand() mec"
Mais heu...je sais pas où il est rand() ni même ou est adresse donc je suis bloqué....
Citer : Posté le 12/06/2018 20:33 | #
T'as le droit de faire ça ? Pas sûr. Pourquoi ce +2 ? Pour l'alignement ?
extern_function:
.data.l _rand
Btw:
Le .l est en trop ; tu n'as besoin de spécifier la taille que quand tu fais des accès mémoire.
Citer : Posté le 12/06/2018 20:40 | #
T'as le droit de faire ça ? Pas sûr. Pourquoi ce +2 ? Pour l'alignement ?
Faut croire que oui.
J'ai désassemblé plusieurs programmes avec rand() et ils faisaient tous ça donc bon...
donc oui pour l'alignement (je pense)
Mais je l'ai enlever et mis .align 4... avant extern_function: ? pourquoi avant ?
extern_function:
.data.l _rand
J'ai toujours le problème de compilation
Citer : Posté le 12/06/2018 20:46 | #
(NB. Utilise le backtick (Alt Gr + 7) pour le code monospacé, si tu peux - c'est plus joli visuellement et pour le code de la page.)
Pourquoi avant ? Parce que .align 4 peut créer des octets de vide et tu veux que extern_function pointe juste sur l'endroit où t'as mis l'adresse de rand().
Ah oui mais ça c'est un artifice de désassemblage. Personne ne code comme ça.
Note à part : pourquoi utiliser r11 pour le faire le saut ?
- Tu vas devoir le sauvegarder et le restaurer
- Comme r0 .. r7 vont être massacrés par la sous-fonction, autant utiliser l'un deux juste avant le saut
Pas facile. Tu as utilisé extern_function sans le +2 comme j'ai suggéré ? Basiquement l'erreur dit que tu as fait référence à un nom mais que soit il n'existe pas, soit il est trop loin (au moins 4k de différence en position absolue, c'est sûr).
Citer : Posté le 12/06/2018 21:07 | #
Ah oui mais ça c'est un artifice de désassemblage. Personne ne code comme ça.
J'ai pas d'exemple donc je fait avec ce que j'ai x)
Note à part : pourquoi utiliser r11 pour le faire le saut ?
- Tu vas devoir le sauvegarder et le restaurer
- Comme r0 .. r7 vont être massacrés par la sous-fonction, autant utiliser l'un deux juste avant le saut
Ha bon ?! même si je ne les utilisent pas ?! (r8~r14)
J'ai pris r11 car je ne l'utilise pas
Bon bah je change ça
Pas facile. Tu as utilisé extern_function sans le +2 comme j'ai suggéré ? Basiquement l'erreur dit que tu as fait référence à un nom mais que soit il n'existe pas, soit il est trop loin (au moins 4k de différence en position absolue, c'est sûr).
Je l'ai bien utilisé sans le +2.
Du coup je fais comment ? je suis bloqué ?
Au pire j'utilise time_getTicks() ou plus précisément le syscall pour la RTC puis je fais le modulo du truc, mais c'est dommage j'aurais aimé réussir à appeler une fonction dans une fonction
Citer : Posté le 12/06/2018 21:14 | #
La fonction qui t'a appelé a sauvegardé des choses dedans. Ils servent à ça ; toi aussi tu as le droit de mettre des choses dedans (si tu les sauvegardes) et alors les sous-fonctions n'auront pas le droit d'y toucher.
Franchement je suis certain que le code suivant passe quand je compile avec as :
sts.l pr, @-r15
mov.l rand, r1
jsr @r1
nop
lds.l @r15+, pr
rts
nop
.align 4
rand:
.long _rand
Vois dans les sources de gint, sinon. Il y en a à pas mal d'endroits.
Citer : Posté le 12/06/2018 21:41 | #
Franchement je suis certain que le code suivant passe quand je compile avec as :
Nan il me dit "300 (E) ILLEGAL MNEMONIC" a cause du .long _rand
Vois dans les sources de gint, sinon. Il y en a à pas mal d'endroits.
OK je vais fouiller un peu pour voir
Citer : Posté le 12/06/2018 21:44 | #
J'ai dit avec GNU as, aka gcc. Utilise .data.l... x)
Citer : Posté le 12/06/2018 21:48 | #
J'ai dit avec GNU as, aka gcc. Utilise .data.l... x)
Yoooooo chui débile j'avais pas kapich
200 (E) UNDEFINED SYMBOL REFERENCE
Citer : Posté le 12/06/2018 21:57 | #
Tu sais quoi, regarde le fichier joint de mon tutoriel de gestion de clavier, il est assemblé pour le SDK et il marche. Les sous-routines qu'il appelle sont des syscalls mais ça ne change rien au problème.