prog-tools add-in for programming on CG50
Posté le 05/04/2025 18:42
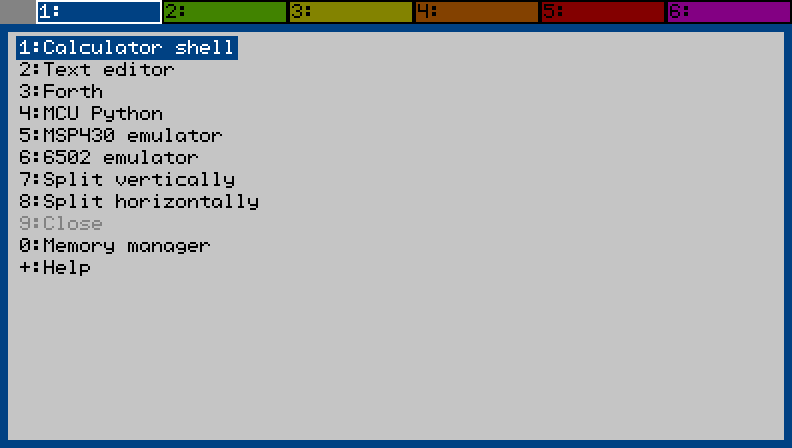
I've been working on an add-in to do programming on the CG50. It has tabs like tmux, and each tab can be split once either vertically or horizontally allowing for up to 12 programs to run at once. Only the currently selected program runs until you switch to another tab or split. I think this will work better than the way the built-in Python does it where you have to save the file and lose your place every time you want to run something.
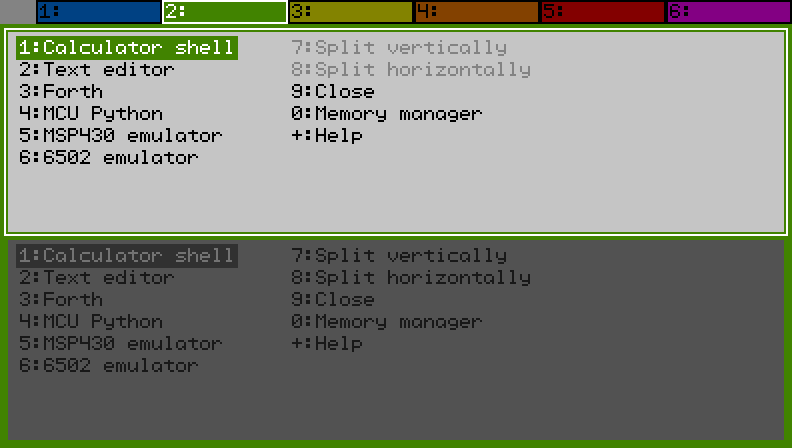
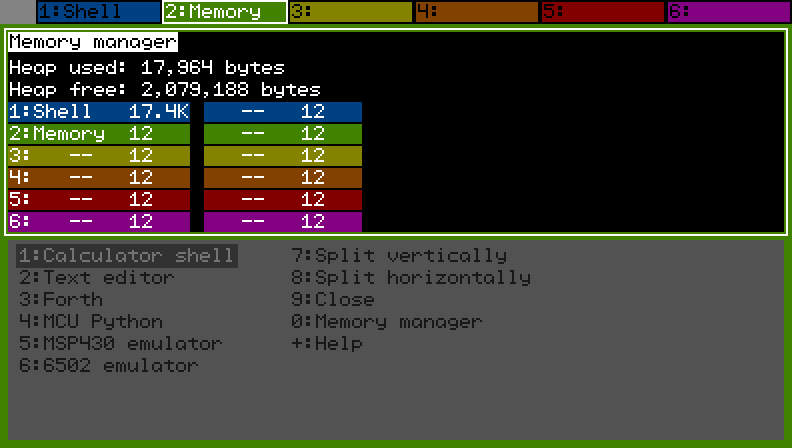
Each of the 12 splits has its own memory in the 2MB of RAM starting at 0x8c200000. When you start a program or move back to a program that's already running, the add-in shifts the memory for the selected program to the top of the heap so it's contiguous with the rest of the free memory and easy to expand.
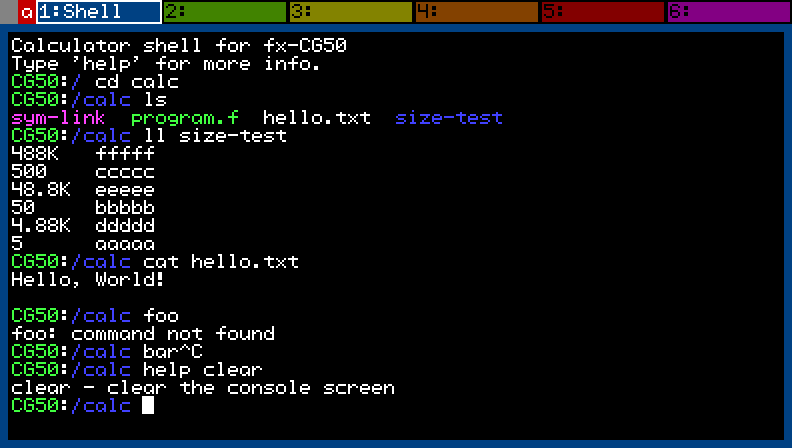
I'm close to being finished with a simple shell so I can manipulate files without having to leave the add-in. Thanks to LephenixNoir for the help with file system operations and everything else. I plan to add a Forth interpreter next to write programs that run on the calculator.
I made a small framework with SDL2 for testing the add-in. It configures the video memory the same as the CG50 so writing a pixel there works exactly the same as on the calculator. It reimplements some of the gint functionality too so I can compile the add-in for linux which is very convenient for testing.
I'll add some more information as I finish more features. Please let me know if you have any suggestions!
GitHub repo here.


Citer : Posté le 28/07/2025 16:38 | #
That's an interesting idea. Most Forths are indeed interpreted with a few exceptions like Mecrisp which runs on microcontrollers like ARM, RISC-V, and MSP430. It produces optimized machine code and does do register allocation to try to avoid the stack where possible which really increases performance by a lot. It might be possible to do that here in a limited way where certain sections are turned into machine code with register allocation and other sections remain interpreted. I'm hesitant to do that because I've had so much luck prototyping on Linux with my SDL2 wrapper and would have to embed an SH emulator for the generated machine code or also generate equivalent x86 code for testing. Maybe when MQ is ready I can switch to that.
Another idea which may be closer to what you suggested is buffering some of the locals in unused registers and doing the assignment by analysis. gcc has an option where you can tell it not to use certain registers which I could then use for locals. I'm not sure the loss in performance would be worth it though. I could also have a script look at the listing from the compiler and note which registers each primitive (DUP, SWAP, DROP, etc) uses then let an analyzer on the calculator use that information to spot free registers to buffer locals in. The primitives tend to be simple and don't use many registers. More complicated primitives might not have any free registers but you would still get a speedup for the stretches of code where those registers aren't being used for anything. The innermost loop above, for example, might benefit from that:
a x + dup c@ 1 - swap c!
What I've been thinking about is combining one or more primitives into one. This is an old idea in Forth where you often see 1+ instead of 1 + or 0= instead of 0 =. I'm not entirely opposed to this but do find it slightly annoying to have to remember which ones are written together and which ones aren't. For example, some Forths also have 2+ but others only have 1+ but no 2+. An extreme example is the HP-48 which is programmed internally in a close relative to Forth. There are hundreds of useful snippets that appear in the ROM followed by a return instruction so you have things like 4PICK+SWAP and DROPSWAPDROP that programmers can jump to to save space. My idea is to figure out a shortened list of primitives I think will offer the most speed up then generate all 2, 3, and 4 primitive combinations. The Forth would peephole optimize the code and replace combinations it knows about with the combined primitive. That way, I can write x 2 + to x without having to remember whether it's 2+ to or 2 +to or 2+to since the peepholer will spot the combination and replace it with the shorter and faster combined primitive.
The thing I'm still trying to figure out now is how to generate all the combined primitives. I was hoping that being careful about how I write them would let me copy and paste their bodies into a combined primitive. Yesterday, I tried the combination DUP AND which should optimize to nothing but the C compiler preserved the writes to the stack from DUP since I don't have a way of telling it that it's not needed. I think modeling the stack operations algebraically somehow (maybe with SSA?) in Python then using that to generate the C code might work. Do you have any advice on how you might do it?
Citer : Posté le 29/07/2025 12:16 | #
Peephole optimization looks promising! I definitely like the sound of that.
In general the overhead from the interpreter makes it difficult for the compiler to figure out what's optimizable. If you write code such as
stack[0] = stack[0] & stack[-1];
the compiler can notice that stack[0] is unchanged but it won't eliminate the write to stack[-1] because someone might look at it later.
Generating the optimized C code yourself is an option. However, I would first like to see a snippet from your attempt to see if it the setup is simple enough that GCC can deal with it.
Also, you may not need to pre-generate everything if you can just do it on-the-fly (JIT style). In this case, you wouldn't be limited in size at all. Edit: Ah but I forgot PC compatibility there for a second, oops.
Citer : Posté le 04/08/2025 06:42 | #
After thinking about it for a while, generating combined primitives doesn't seem that feasible. I came up with a list of 52 primitives I'd like to be able to optimize and cut it down to about 30 essential ones. The peephole optimizer would need to work with combinations up to 4 long to optimize common runs like x 1 + to x (ie x+=1) which means 30^4 = 810,000 combined primitives. Even if half of these could be eliminated for containing redundant operations like SWAP SWAP or DUP DROP, it's still way too many to accommodate.
I came back to the idea of generating machine code which you mentioned and decided to split the testing program into two parts. The first part is now a TCP server that creates an SDL2 window to display the screen and receive keyboard input. The second part contains the main program functionality and connects to the first part over TCP for input and output. Since the main program doesn't need SDL2 anymore, I can compile it to run under Linux for SH4 then run that in qemu-sh4eb-static (ie qemu-user not qemu-system) which has no problem connecting over TCP. This has all the same advantages of debugging the program on Linux as before such as console output and logging while letting me poke SH4 machine code into memory and jump to it.
Getting the compiler set up for this was a little challenging. The sh4-linux-gnu-gcc package is meant for little-endian targets. There is a compiler option to compile for big-endian but the linker does not have an emulation target for sh4eb. I didn't have much luck compiling sh4eb-linux-gnu-gcc myself and switched to musl-cross-make to compile a musl-based toolchain which was very easy.
The first test I did was poking 0x00, 0x0B, 0xE0, 0x2A into memory which is the machine code for rts / mov #42,r0 then casting to a function pointer returning an int. The function call returns 42 in qemu but was returning 12 on the calculator until I put some code between the memcpy and function call which confirms the machine code was written. It also returns 42 correctly with just a short for loop before the function call. Any idea what's going on? I'm guessing the processor doesn't wait for writes to complete when it fetches instructions the same way it waits when fetching data.
Citer : Posté le 04/08/2025 08:13 | #
What a move! I'm impressed that you went all the way with emulation on Linux. The toolchain setup is indeed not that easy. It's great that you pulled it off!
For code generation on the calculator there are multiple cache hurdles:
1. First, you store the code opcodes to memory with a memory access instruction. This is likely gonna be in P1, so cached.
2. Therefore, you must then write back the associated operand cache lines to memory.
3. Then, you must also purge the associated instruction cache lines, otherwise you may still run old code.
4. Finally you can enjoy!
Here's an example (untested). Cache lines are 32 bytes so the loops run on 32-byte blocks.
void ocbwb(void *ptr, size_t size) {
uintptr_t block = (uintptr_t)ptr & -32;
uintptr_t end = (uintptr_t)(ptr + size - 1) & -32;
for(; block <= end; block += 32)
__asm__("ocbwp %0" :: "r"(block));
}
/* Instruction Cache Block Invalidate */
void icbi(void *ptr, size_t size) {
uintptr_t block = (uintptr_t)ptr & -32;
uintptr_t end = (uintptr_t)(ptr + size - 1) & -32;
for(; block <= end; block += 32)
__asm__("icbi %0" :: "r"(block));
}
int generate_and_run_function() {
uint16_t *ptr = /* malloc, static buffer, whatever */;
ptr[0] = 0x000b; // rts
ptr[1] = 0xe02a; // mov #42, r0
size_t size = 4;
ocbwb(ptr, size);
icbi(ptr, size);
int (*genfunc)(void) = ptr;
return genfunc();
}
Citer : Posté le 03/12/2025 10:35 | #
I made a little progress on generating optimized machine code. I decided to build a prototype in Python then move the optimizations worth keeping to C. The program is here: optimize.py and test cases here: results.txt
It starts with an algebraic stack that models the program’s effects. Calculations generate statements similar to SSA, and their stack effects are modelled. The final stack picture tells where calculated values should be stored by the generated machine code and helps spot useless operations:
Forth:
Statements:
S[0] = +(2 3)
S[1] = *(S[0] 4)
S[2] = *(S[1] 5) <-Unused!
Stack: 1 S[1]
The optimizer runs the following steps repeatedly until the statements settles and there are no more changes to be made:
- Combine additions: 2+x+3+x -> 5+x
- Combine multiplications: 2x+3x -> 5x
- Cancel divisions with multiplication: x*y/y -> x but no change for x/y*y
- Combine exponents: 3x^2 * 2x -> 6x^3
- Eliminate identical statements
- Identities: x*0 -> 0, x/x -> 1
Here’s an example (x and y are local variables):
Forth:
Statements:
S[0] = +(5 y)
S[1] = *(3 x)
S[2] = +(S[0] S[1])
S[3] = +(x x)
S[4] = +(S[2] S[3])
S[5] = +(S[4] -1)
Optimized statements:
S[2] = +(5 y S[1])
S[3] = *(2 x)
S[4] = +(5 y S[1] S[3])
S[5] = +(4 y S[1] S[3])
S[5] = +(4 5x y)
Now that this is finished, I don’t think it’s worth the effort to do this kind of algebraic optimization on the calculator. The programmer can do most of these without the compiler’s help. I think it makes sense to keep tracking stack effects and focus on just a few of these optimizations. Next, I’ll look at register allocation and generating machine code.
Citer : Posté le 18/12/2025 15:49 | #
One thing I have thought a lot about is how to prevent the stack underflow and overflow from crashing the calculator. A lot of Forths don't bother checking and allow the program to crash which I want to prevent from ever happening. The standard way of doing it is checking the stack pointer on every operation. Pseudo-code:
{
if (sp==0) error(UNDERFLOW);
else sp--;
}
void dup()
{
if (sp==STACK_SIZE) error(OVERFLOW);
else
{
stack[sp]=stack[sp-1];
sp++;
}
}
program={&drop, &drop, &dup};
Another way to do it is to use a circular stack where underflow wraps around to the end of the stack and overflow wraps around to the beginning of the stack. This might cause the program to behave unpredictably since no error is generated but will not cause a hard crash since it never accesses memory out of bounds. This is what I have been doing until now. Pseudo-code:
void drop()
{
sp--;
sp=sp_base|(sp&STACK_MASK);
}
void dup()
{
temp_sp=sp_base|((sp-1)&STACK_MASK);
stack[sp]=stack[temp_sp];
sp++;
sp=sp_base|(sp&STACK_MASK);
}
program={&drop, &drop, &dup};
When I was thinking about generating machine code, I thought about modeling all of the stack effects beforehand and realized this will work with regular code too. For stack manipulations (SWAP, DROP, etc) and calculations, the compiler can calculate what stack checks need to be done for each one and combine it into one big check. Pseudo-code:
{
if (sp<2) error(UNDERFLOW);
}
void drop()
{
sp--;
}
void dup()
{
stack[sp]=stack[sp-1];
sp++;
}
program={&check_2_0, &drop, &drop, &dup};
The compiler sees that drop drop dup decreases the stack pointer by 2 then increases it by 1. Since the stack pointer is now still less than where it started, there's no reason to waste time checking if dup can overflow since it obviously can't. Also, the two individual checks in drop to prevent underflow can be combined into one check. I have functions hardcoded for all combinations of pushing 0-7 values and popping 0-7 values. The compiler in this case selects check_2_0 to check that there are at least two items on the stack and inserts it before drop drop dup runs as shown above. My prediction was that this would be much faster than the circular stack, but it runs the n queens benchmark in 39ms which is slightly slower. I'm still trying to figure this one out. It seems the overhead of the extra call to check_2_0 is more expensive than a lot of ANDing and ORing for the circular stack. For example, in the n queens code above, this stretch of instructions only needs one call to check_3_0 yet would need 20 AND/OR pairs for masking with a circular stack:
Citer : Posté le 18/12/2025 17:05 | #
I love how this thread is just more and more static analysis <3
Not clear to me why a single call to check_3_0 would be slower in this case. There's a chance drop() and dup() might be getting very optimized. What's the stack size?
Citer : Posté le 20/12/2025 16:29 | #
The stack size is 256, so doing a comparison to see if the next primitive will overflow loads a value from the constant pool. It might be slightly faster to make the stack small enough to load the comparison value in one cycle.
I tried compiling with O2 and O3 rather than Os. O2 brings the time down to 31ms from 39ms and O3 is worse at 34ms. I also added the changes I mentioned before with musttail where primitives load the next primitve directly rather than jumping back to the dispatch loop. This brings the time down to 28ms for O2, O3, and Os. The musttail attribute is only available in gcc 15, so I compiled a few of the C files to assembly with gcc 15 then passed the result to fxsdk with the rest of the C files. Some of the primitives reference gint and libprof, so I copied the include directory from fxsdk to my sh-elf-gcc 15 container.
Next, I'll work on replacing some of the instructions with machine code.