MQ : Émulateur add-ins universel
Posté le 28/05/2025 20:22
Parmi les
projets de 2025 il y a tout un plan pour préserver les contenus du site, notamment les vieux programmes. La base de programmes de Planète Casio n'est pas beaucoup maintenue et on ne traque pas vraiment ce qui est encore jouable ou pas.
Les projets d'émulateurs c'est pas nouveau, c.f.
*,
*,
* et j'en oublie. Initialement je pensais repartir d'un existant, mais finalement j'en ai commencé un from scratch en voyant le cahier des charges :
- Il faut pouvoir émuler à la fois les Graph mono et les Prizm et à la fois les SH3 et les SH4 ;
- Il faut que ça puisse tourner sur le site donc compiler vers WebAssembly et optimiser raisonnablement (téléphones etc. ont pas des perfs de dingue) ;
- Il faut émuler pas mal de trucs matériels, donc assez bas-niveau, pour bien couvrir les add-ins et potentiellement l'appli PRGM pour émuler les programmes Basic ;
- Et si on fait tout ça ce serait criminel de pas s'en servir pour développer/debugger, ce pour quoi une GUI plus grosse que juste l'écran est nécessaire (et/ou gdb).
Les détails techniques, pour ceux que ça intéresse, c'est : pur C, tourne sur
Azur par facilité (GUI en OpenGL avec
ImGui + compile pour Linux et WebAssembly), le décodeur est un arbre de
switch généré automatiquement et la mémoire est hiérarchique par blocs de 1 Mo, 4 ko, et 1 octet.
L'état actuel (Mai 2025) c'est : on peut faire tourner quelques add-ins sur CG, y'a des syscalls mais peu, y'a une partie du matériel émulé pour faire tourner gint ; en gros si vous prenez un add-in aléatoire ça va probablement pas marcher, mais pas loin.
Voici le dépôt et au passage à quoi ressemble l'interface : y'a tous les trucs techniques nécessaires pour debugger.
» Dépôt Git Lephenixnoir/mq «
» Instance Web (expérimentale) «
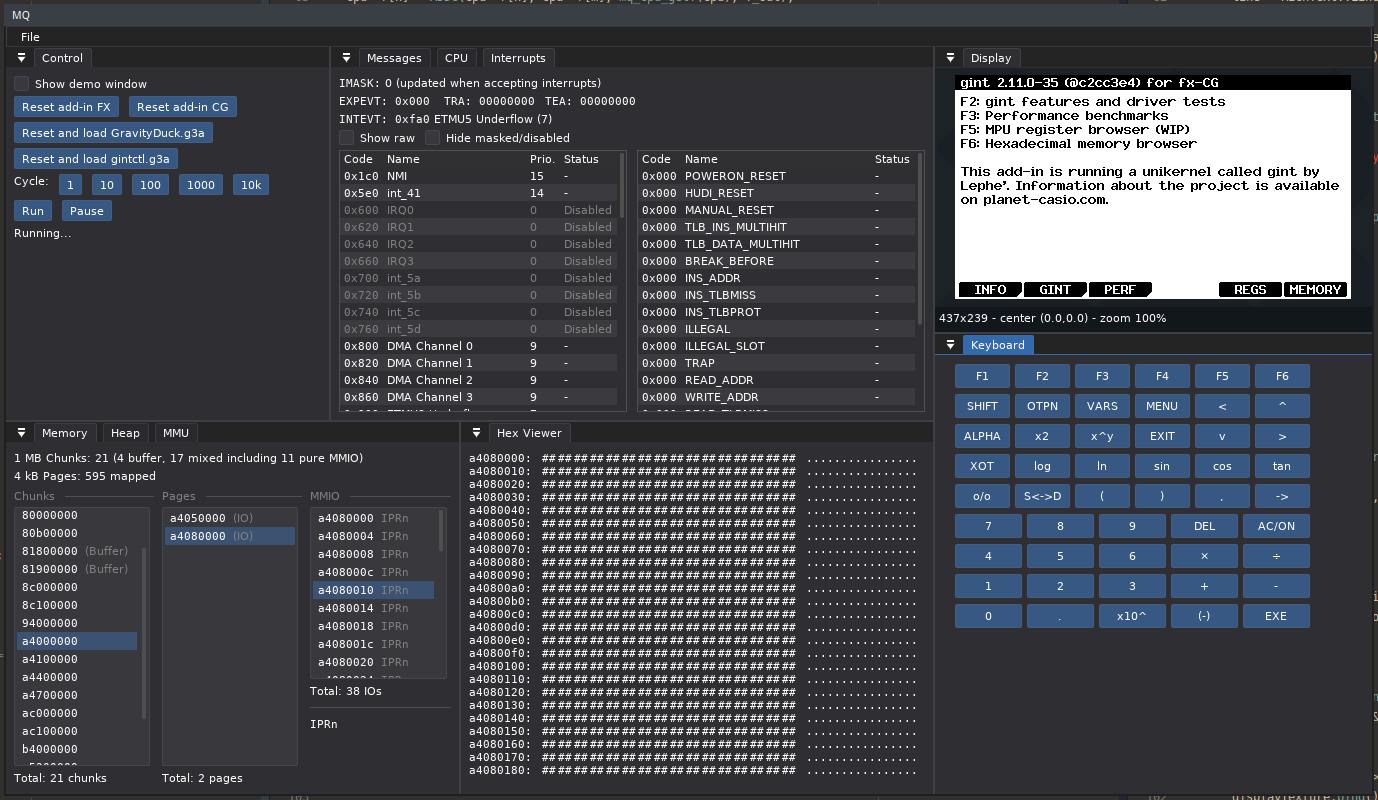
J'ai pas encore de build pour le web sur lequel vous pouvez cliquer et tester tout de suite, mais vous pouvez compiler depuis le dépôt.
Voilà plus de nouvelles bientôt j'espère.

 Fichier joint
Fichier joint



Citer : Posté le 05/10/2025 20:06 | #
Je me joins à Cake pour aussi vous féliciter. C'est vraiment un superbe boulot que vous faites tous sur MQ.
Je suis admiratif des progrès qui sont faits sur l'émulations des diverses machines.
En quelques mois, on passe d'un prototype à un émulateur qui fait tourner un grand nombre d'addins, c'est vraiment la classe internationale
Bon courage à vous et à lire vos splendides progrès avec le plus grand plaisir.
<3
Citer : Posté le 06/10/2025 12:26 | #
fantastic work!!
is there a available online link?
btw the display on the fx-9750GII runs at 64hz
(not the usual 60hz)
Citer : Posté le 10/10/2025 18:17 | #
Merci pour tous les commentaires gentils. <3 Avec Yatis on s'éclate sur le projet, et y'aura sans doute encore beaucoup de développements dans le futur.
Pour info, actuellement on finit une première release et ensuite on passera à autre chose pour un moment.
D'ailleurs Cake l'émulateur de Renesas est pas mauvais du tout je pense, il va probablement plus vite que le nôtre actuellement et ce ne sera peut-être pas facile à battre.
Redcmd: there's no server serving the app right now, if you want to try it you need to build it yourself (Linux or emscripten targets). Or if you want a one-off build I can also provide one.
The UI refresh rate of 60 Hz is independent from the display refresh rate. Although we could maybe emulate the T6K11's delay characteristics to "organically" reproduce the gray effect. Or try to detect the fast swapping analytically.
Citer : Posté le 13/10/2025 17:50 | #
Je ne suis pas online souvent mais c'est super de voir comment ça progresse, ça évolue vraiment vite !
Citer : Posté le 21/10/2025 19:46 | #
Du coup Yatis a mis la main sur une une optimisation de décodage/exécution (autre page à ce sujet) qui serait applicable pour nous. En plus c'est un mi-chemin par rapport au JIT donc une très bonne idée. Du coup on est partis sur ça !
Pour l'instant j'ai surtout fait plein de simplifications dans la boucle critique pour préparer ce travail. Croyez-le ou non, j'ai perdu des FPS sous Linux (y'avait un écran dans Boson X qui faisait 50 FPS et maintenant fait 46 FPS), mais sur emscripten ça a beaucoup aidé ! Dans le premier niveau de Boson X (toujours le plus dur en termes de performance !), dans la navigateur avant je faisais 4-8 FPS et maintenant je fais plus genre 8-16.
L'endgame c'est d'avoir de bonnes perfs dans le navigateur puisque la plupart des utilisateurs s'en serviront probablement pour tester des jeux sur le site (s'ils n'ont pas la calto). Du coup, de ce point de vue-là on progresse !
Yatis arrive à la fin de la capture vidéo, on vous tient au courant.
Citer : Posté le 21/10/2025 20:17 | #
Stylé les computed goto, c'est très intéressant!
Citer : Posté le 26/10/2025 14:08 | #
Point performances : l'émulateur officiel de CASIO utilise au moins en partie du code de Renesas pour le coeur, l'émulation du CPU et des registres périphériques. De ce qu'on a vu avec Yatis, c'est du code très optimisé avec notamment les computed gotos. Malgré tout, l'émulateur officiel doit faire quelque chose de travers parce que ses performances sont abysmales, il tient genre 5 FPS sur Gravity Duck là où MQ monte à 150. C'est même pas comparable.
L'émulateur de circuit10 (qui supporte "que" gint sur la CG, mais est déjà très bon) va beaucoup plus vite. Longtemps il exécutait Duet entre 1.5x et 2x plus vite que MQ et je comprenais pas pourquoi. En fait il s'avère que Duet a un limiteur à 30 FPS et l'émulateur de circuit10 est pas super précis dans son émulation du temps du coup Duet se donnait plus de marge.
En prenant une version sans limiteur MQ va finalement un chouille plus vite (avant les computed gotos), environ 5% de plus pour être précis.
Bon ce ne sont que des exemples individuels mais on approche du point où MQ est à la fois l'émulateur le plus compatible et le plus rapide, ce qui est cool
(Pour info Boson X crashe dans l'émulateur officiel et je sais pas encore si c'est un bug de Boson X ou un bug de l'émulateur officiel... à ce stade tout est possible, Boson X est un monstre sur ce plan)
Citer : Posté le 26/10/2025 20:26 | #
J'ai profilé Afterburner sur Firefox (Librewolf 138.0.1 Linux sur un AMD 4500U), et les résultats sont les suivants :
- Le printf de emscripten est très lent. Au point où la ligne 404 de gui/gui.cc prend 11% du temps CPU de la thread principale et ralentit (qualitativement) pas mal l'émulateur
- La MàJ des timers prend 34% du temps d'émulation, surtout puisque chaque appel repasse en JS.
D'autant plus que le timer utilsé (performance.now) n'a qu'une résolution de 20 à 1000us selon les navigateurs (voir https://developer.mozilla.org/en-US/docs/Web/API/Performance/now , et https://github.com/w3c/hr-time/issues/56 ).
Je suis actuellement en train d'essayer de faire un patch pour ce second point
Caltos : G35+EII, G90+E (briquée
Citer : Posté le 26/10/2025 22:18 | #
Merci ! Très utile ! Je n'ai jamais programmé pour la haute performance sur le web donc je découvre des trucs. En natif clock_gettime() est dans le vDSO donc tu peux l'appeler très libéralement...
Pour les timers, mon plan moyen-terme existant est de modifier la façon dont le "temps réel" est calculé pour rendre l'exécution plus déterministe, afin de permettre (1) des replays sur le même binaire, ce qui est assez facile, (2) des replays sur des binaires modifiés (pour exécuter le même setup tout en développant), ce qui est plus tendu.
La dernière idée que j'étudie est de mesurer le temps d'exécution de chaque run de 20000 cycles dans le contrôleur et d'en déduire une fréquence CPU interpolée pour les 20000 cycles suivants. De cette façon y'a qu'une valeur de temps à sauvegarder par run et pas une pour chaque exécution d'instruction qui donne lieu à une requête sur le temps.
Citer : Posté le 07/11/2025 19:27 | #
Bon donc on a enquêté davantage avec Yatis sur les perfs navigateur.
Première observation, Performance.now n'est pas le problème dans le main thread contrairement à ce que j'avais cru, c'est juste que les mutex bloquent et quand ils sont bloqués il sont dans un boucle d'attente qui appelle Performance.now. Par contre c'est un problème dans le thread d'émulation.
Deuxième observation, dans mes tests le thread d'émulation passait un temps considérable dans une fonction appelée getWasmTableEntry qui est normalement utilisée pour indexer les fonctions chargées dynamiquement, en gros comme la PLT dans un build dynamique. Étonnant puisqu'on compile tout en statique.
En fait c'était causé par un usage de setjmp/longjmp dans la boucle principale, qui nécessite un retour en js pour la sauvegarde de contexte (et en particulier un passage dans la table dynamique), qu'on payait très cher. Solution : revenir au test de mach->stuck à chaque cycle. Fcalva l'a peut-être pas vu parce que c'est un changement super récent.
Du coup après avoir réparé cette broutille on revient à la situation donnée par Fcalva, qu'on va essayer d'améliorer.
Citer : Posté le 26/11/2025 19:29 | #
De retour pour un nouveau progress report !
Déjà presque 2 mois depuis que le précédent rapport a été publié, beaucoup de changements ont eu lieu, que ce soit dans le cœur de l'émulation, la stabilité générale du projet, la GUI, ... mais aussi des changement dans la vraie vie (je veux dire, Lephe est littéralement devenu docteur entre-temps!)
Cependant, contrairement à la dernière fois, il n'y n'a pas eu beaucoup de changements "visuels" concernant l'émulation, principalement beaucoup d'optimisation et de nettoyage de ce coté la, donc le rapport sera beaucoup plus petit et moins graphique que la dernière fois. Ceci étant dit, commençons!
Le support du recording et des screenshots
Teasé depuis plusieurs mois, ces deux fonctionnalités sont maintenant officiellement intégrées dans MQ!
Comme vous pouvez le constater, l'interface de la fenêtre record a été significativement améliorée depuis notre dernier compte rendu. La nouvelle fenêtre combine la capture d'écran et l'enregistrement vidéo, tout en offrant de nouvelles options de configuration. Et si vous avez été attentif, vous avez aussi remarqué que la barre de statut embarque maintenant quatre nouveaux boutons qui répliquent ceux de la fenêtre record. Vous n'avez donc même pas besoin de vous rendre dans la fenêtre pour démarrer quoi que ce soit!
Pour information, la fonctionnalité de screenshot est disponible sur toutes les plateformes supportées (Linux et web), a contrario de l'enregistrement qui désactivé pour la version web. A savoir que vous pouvez aussi, à la compilation, ne pas inclure les fonctionnalités de recording, ce qui est utile si vous n'avez pas ffmpeg et toutes les libs d'installé sur votre machine.
Maintenant, laissez-moi vous conter les problématiques techniques qu'on a rencontrées au cours du développement.
You're too slow
La rapidité de l'encodage. C'était le point mentionné la dernière fois où j'expliquais que l'encodage des images pour la vidéo était super violent côté CPU (un jeu à 60FPS descendait vers 5/6FPS) et qu'on allait devoir supporter les accélérations matérielles et peut-être meme mettre en place un thread d'exécution spécialement dédié pour la vidéo.
Eh bien, il se trouve qu'en écrivant un programme de tests pour les accélérations matérielles (que vous pouvez retrouver ici d'ailleurs), on s'est rendu compte avec Lephe que l'encodeur que j'utilisais, libvpx-vp9, était tout simplement abyssalement lent et qu'en utilisant un encodeur plus simple comme libx264, on avait tout simplement un x60 (voire plus) en termes de perf'. Et en changeant uniquement l'encodeur dans MQ, l'enregistreur s'est mis à fonctionner sans qu'on ressente de ralentissement sur l'émulation (entendez par là, sans avoir besoin d'accélération matérielle ou de threading)!
Ce qui change entre les deux codecs est basiquement le taux de fidélité des images enregistrées et le taux de compression (la qualité finale de la vidéo en somme). libvpx-vp9 (VP9) vise à avoir le moins de perte de qualité avec un taux de compression le plus élevé possible, à contrario du libx264 (H264) qui s'embête moins avec ces détails et qui vise juste l'efficacité. Ce qui explique pourquoi une telle différence de performance entre eux.
Bon...comme l'implémentation de l'accélération matérielle était en train d'être finalisée, on l'a quand même intégrée à MQ juste pour avoir un excès d'opulence technique pour le projet (slay). Cependant, comme détecter automatiquement les encodeurs hardware peut être assez long, si vous voulez tester cette fonctionnalité, vous devez explicitement cliquer sur le bouton detect de la fenêtre record pour lancer la détection, mais il risque d'y avoir un petit freeze de quelques secondes le temps qu'on trouver les encodeur disponible sur votre machine. (Note: de vous à moi, vous n'avez pas grand intérêt à utiliser un autre encodeur que la libx264 qui est sélectionné par défaut).
Nivens McTwisp 🐇
Un autre point où on a mis longtemps à prendre une décision, c'est pour la gestion du temps dans l'encodage. Avant, peu importe à quel point l'émulation était ralentie ou accélérée, le recordeur attendait patiemment une nouvelle frame et l'ajoutais à la suite dans la vidéo. Ce qui donnait une vidéo "fluide", mais qui ne reflétait pas la réalité. Ce qui pouvait donner des vidéos étranges sur des jeux qui n'arrivent pas à atteindre les 60FPS dans l'émulation (e.g. BosonX). (Note : toutes les vidéos enregistrées se synchronisent sur la fréquence de la GUI, à savoir 60FPS)
On a donc nettoyé un peu le système interne pour avoir constamment une copie du dernier frame affiché à l'écran (corrigeant pas mal de bugs critiques (deadlock) liés au thread d'émulation au passage) et mis en place le fait de calculer dynamiquement "où est-ce que va l'image" dans la vidéo (PTS). Cette approche, bien que fonctionnelle sur papier, fut un échec cuisant, pour la simple et bonne raison que les décodeurs vidéo ne supportent pas forcément le fait d'avoir "des sauts" entre les frames.
Basiquement, prenons gintctl qui rafraîchit l'écran uniquement pour afficher quelque chose. Quand on démarre l'enregistrement, on mettait la première image au début de la vidéo, puis on attendait une nouvelle image. Si vous attendiez 10 secondes avant d'avoir un nouveau rendu, on disait à l'image actuelle de la vidéo "toi, tu dure 10 secondes", ensuite on "sautait" 10 secondes dans la vidéo pour y mettre la nouvelle image ; et ainsi de suite pour chaque frames. L'idée étant de gagner le plus possible de ressources (CPU, mémoire) lors de l'enregistrement et de reduire, au passage, la taille du fichier final.
Techniquement c'était fonctionnel....mais pour les lecteurs vidéo...pas du tout. Figurez-vous que tous les lecteurs ne réagissaient pas de la même façon à nos vidéos, c'était très aléatoire entre plantage (VLC) et mauvais rendu. Après pas mal de tests et de recherches, on est arrivé à la conclusion que le MP4 (conteneur de la vidéo) et/ou les encodeurs qu'on utilise (VP9/H264) ne supportaient pas notre approche et on a simplement fini par respecter les 60 images par seconde, quitte à réécrire plein de fois les mêmes frames, et tout s'est mis à fonctionner proprement.
En conséquence, l'encodage a pris un gros coup en consommation de ressources, mais n'a pas impacté tant que ça la taille des vidéos (tout dépend du format, mais dites-vous que chaque image de la vidéo contient "que" les differences entre l'image d'avant et/ou d'après. Du coup, s'il n'y a pas beaucoup de différence, eh bien ça ne pèse pas beaucoup).
Le plus important, c'est que ça fonctionne!
Operation goto!
Comme Lephe l'avait mentionné, je suis tombé sur un article parlant de "computed goto" qui pourrait être une marche intermédiaire pour le JIT qu'on a prévu et qui va demander beaucoup d'ingénierie. Comprenez que cette partie concerne le coeur de MQ (l'emulation) et le modifier peut avoir des impacts énormes sur la fiabilité (surtout quand on commence à tricher pour aller plus vite!).
Le principe du "computed goto" est relativement simple.
Actuellement, dans la boucle principale de l'émulation, pour chaque instruction, on effectue le décodage de l'instruction en cours ainsi que l'appel à sa fonction. Ce qui implique un premier saut vers la fonction (e.g mov_l() pour l'instruction mov.l) puis un saut de retour (return)...à chaque instructions...et on fait ça plusieurs millions de fois par secondes...donc fatalement on passe la plupart de notre temps à faire des sauts plutôt que de faire des trucs utiles (ce qui n'est pas pour me déplaire, j'ai été 2 fois champion de France de trampoline, mais tout de même!).
L'approche du "computed goto" reste exactement comme notre boucle actuelle, mais au lieu de faire des appels de fonction, on utilise les goto à la place. La grosse différence, c'est qu'on n'a pas à se soucier de faire un saut pour revenir (return) ou d'envoyer les arguments correctement à la fonction, ... on a donc "juste" qu'un seul saut à faire au lieu de deux. Vous combinez ça à d'autres techniques assez spécialisées pour aider le compilateur à optimiser le code, et on devrait gagner quelques perfs (surtout niveau web où on en manque).
Ceci étant dit, ce n'est pas aussi simple que ça à mettre en place, parce que comme vous pouvez le voir sur le pseudo-code plus haut, la technique des "goto" repose sur une table de goto....et il faut la générer...et ce n'est pas si simple vu qu'il faut analyser le code qu'on veut exécuter à l'avance...mais c'est exactement le bon début pour la mise en place du JIT à l'avenir, puisqu'on aura aussi besoin de cette exacte même analyse!
Pour l'instant, Lephe a beaucoup nettoyé la boucle principale du décodage afin de la simplifier le plus possible et de préparer le terrain pour cette technique (c'est une opération à coeur ouvert, donc on est très prudent). On a légèrement perdu en perf côté Linux en attendant (ce qui est assez surprenant honnêtement), mais on a facilement doublé côté web. D'ailleurs, merci à Fcalva de nous avoir mis sur la piste d'inspection des performances côté web, on a plus grandement optimisé les versions récentes de MQ pour le web et isolé les points de ralentissement. Une fois la mise en place des "computed goto", on va sûrement faire une passe pour essayer d'améliorer encore plus lef perf' côté navigateur.
En tout cas c'est très prometteur et j'ai hâte de voir combien on va gagner des perfs à l'avenir (ou si ça va être en petard mouillé)!
Quid de la suite ?
Eh bien Lephe s'occupe de la partie "computed goto" et les optimisations côté navigateur et moi je m'occupe de la mise en place d'une CI/CD pour vous proposer des releases avec des binaires tout frais, prêts à être utilisés (avec d'autres surprises dans ma besace, mais je vous en parlerai en temps et en heure) et je referai sûrement une passe sur la table de compatibilité entre-temps.
Avec l'arrivée du nouveau coeur ainsi que du système de release, on devrait s'approcher d'une version qui nous satisfera assez pour passer à autre chose pendant quelque temps (toujours en lien avec les calto bien sûr!).
Merci de nous suivre dans cette aventure, 2026 va s'annoncer intéressant!
Citer : Posté le 26/11/2025 20:35 | #
C'est vraiment du super boulot. J'ai hâte que vous implémentiez les syscalls vers le filesystem pour pouvoir tester quelques addins qui font appels à ceux-ci et qui actuellement ne fonctionnent pas (mais ils ne crashent pas, ce qui est déjà particulièrement remarquable).
C'est vraiment du très lourd. Encore bravo.
Citer : Posté le 01/12/2025 06:21 | #
Franchement super boulot
Ecrivez vos programmes basic sur PC avec BIDE
Citer : Posté le 02/12/2025 17:50 | #
Très joli progrès, merci pour ces updates détaillées !
J'aimerai potentiellement continuer à avancer côté fx et j'ai des questions concernant deux points:
Premièrement du côté des syscalls BFile/MCS, ayant implémenté la plupart de ces fonctions sur mon émulateur j'ai quelques bases concernant leur fonctionnement.
La précédente update indique que:
La plus simple serait de faire une bête interface ordinateur <-> MQ via des open(), read(), write(), close() qui pourrait fonctionner dans la majorité des cas et qui ne devrait probablement pas trop être compliquée à mettre en place.
J'avais également suivi l'approche "bête interface ordinateur <-> émulateur": les fichiers sont stockés dans un répertoire sur le PC et les syscalls peuvent interagir avec ce répertoire. Cependant je n'ai pas réellement émulé cette mémoire, aucune adresse dans l'émulateur ne permet d'accéder à ces données. Quelle serait la bonne façon de procéder sur mq pour que l'émulateur reste fidèle à la machine, est-ce qu'il faudrait copier la mémoire permanente dans une zone de l'émulateur à son lancement ?
Mon deuxième point concerne gint. Voici le log qui apparait lorsqu'on lance le sample fxSDK créé par gint sur mq:
warning: [PC=00303ae0] unhandled read @ 88040000 (1B) -> returning 0
warning: [PC=00303ae2] unhandled write @ 88040000 (1B) -> ignoring
warning: [PC=00303ae4] unhandled read @ 88000000 (1B) -> returning 0
warning: [PC=00303ae6] unhandled write @ 88000000 (1B) -> ignoring
warning: [PC=00303aea] unhandled write @ 88040000 (1B) -> ignoring
debug: icbi instruction used and ignored
warning: [PC=00300aee] unhandled read @ fec10004 (4B) -> returning 0
warning: [PC=00300af2] unhandled read @ fec10024 (4B) -> returning 0
warning: [PC=00300af6] unhandled read @ fec10008 (4B) -> returning 0
warning: [PC=00300afa] unhandled read @ fec10028 (4B) -> returning 0
warning: [PC=00300afe] unhandled read @ fec1000c (4B) -> returning 0
warning: [PC=00300b02] unhandled read @ fec1002c (4B) -> returning 0
warning: [PC=00300b06] unhandled read @ fec10014 (4B) -> returning 0
warning: [PC=00300b0a] unhandled read @ fec10034 (4B) -> returning 0
debug: Handling interrupt 0xfa0
Les premiers unhandled read/write autour de l'adresse 0x88040000 concernent la détection d'extension de RAM faite par gint, ce qui va probablement causer des soucis pour certains addins qui l'utilisent.
Pour supporter ces accès, si je ne me trompe pas il faudrait émuler une zone de mémoire physique qui est mappée à la zone mémoire virtuelle équivalente ?
Dans quelle partie du code est-ce que ça se ferait, mq_machine_setupHardware() ?
Concernant les logs autour de 0xfec10004, ils ont l'air de correspondre à l'initialisation du module BSC (Bus State Controller) fait par gint, mais je ne suis pas vraiment familier avec ce module, quelles sont les conséquences de ces unhandled read/write ?
Merci pour vos réponses, et j'en profite aussi pour dire un grand bravo au Dr. Lephe pour ta thèse
Citer : Posté le 16/12/2025 18:56 | #
Hello !
J'essaye de lancer un programme g3a, lui il se lance bien mais il a besoin d'un fichier .bin (avec std::fopen) et j'ai beau le mettre à côté du .g3a, l'émulateur ne le trouve pas
Albert Einstein
Citer : Posté le 16/12/2025 19:04 | #
Salut !
Oui c'est totalement normal, on n'a pas implémenté l'interface BFile pour l'instant. Il me semble que Lephe a un PoC qui traîne, mais faut qu'on trouve le temps de l'intégrer :/
Citer : Posté le 26/01/2026 19:03 | #
J'avais fait du computed-goto quand j'ai fait la vm de mon langage de programmation. Je croyais que c'était aussi le cas dans mq... Du coup je suis ravi d'entendre que ça va arriver.
Citer : Posté le 07/04/2026 20:53 | #
Première release de 2026 (un peu en retard)! J'espère que tout se passe bien de votre côté!
Quoi de mieux pour commencer l'année qu'un petit progress report de MQ? Au programme : une cinquantaine de commits, beaucoup de refacto ainsi qu'une grosse passe sur la stabilité de l'émulation côté calculatrice mono.
Petit aparté avant de commencer : l'état actuel de MQ nous satisfait grandement et nous allons, pour de vrai cette fois-ci, basculer sur d'autres projets pendant quelque temps. On vous donne plus d'informations à la fin du message.
Systeme de release
L'une des grosses nouveautés qui devrait grandement vous aider et vous faire plaisir, c'est la mise en place d'un processus de release automatisé (CI/CD) qui vous donne des binaires tout frais! Plus besoin de faire 40 commandes de build pour tester l'émulateur! Vous avez juste à télécharger le binaire approprié, y ajouter les droits d'exécution et hop, MQ se lance!
A noter aussi qu'une instance web a été déployée ici -> https://www.planet-casio.com/mq/index.html
On vous invite donc à tester l'émulateur sur le web ainsi qu'à jeter un œil à la release de MQ sur son dépôt! Release qui se dote aussi d'un changelog (...bientôt), plus minimaliste que les Progress Report si jamais vous loupez nos prochains postes.
Le système de release a été l'un des chapitres principaux pour cette nouvelle version du projet. Beaucoup de code a dû être refondu, beaucoup de tests et d'échecs, mais nous y sommes arrivés ! Et ce n'était pas une mince affaire ! Les fautifs principaux dans cette histoire sont ffmpeg et les différences subtiles entre GitHub et Forgejo concernant la CI/CD (qu'on nommera "CI" ou "action" par la suite).
Concernant le premier fautif, il faut savoir que ffmpeg (la librairie qui permet de faire l'enregistrement vidéo) est assez complexe à construire et encore plus à "embarquer" dans un binaire (eg. a compiler comme une simple librairie statique). Déjà parce qu'il y a plusieurs librairies différentes au sein même du projet, mais surtout qu'une bonne partie de ffmpeg repose sur d'autres librairies externes pour fonctionner, notamment celles concernant les accélérations matérielles! Et bien sûr, ces librairies ne se build pas et/où sont extrêmement difficiles à obtenir à cause des licences et de l'enclave infinie avec le système, voire le kernel, voire le matériel directement... bref, c'est un enfer abyssal de ce côté-là pour l'avoir avec toutes les fonctionnalités en standalone.
C'est pourquoi on a fait le choix, dans un premier temps d'embarquer ffmpeg avec uniquement les codecs logiciels qui, eux, sont raisonnablement facile a avoir, puis, dans un deuxième temps, on a décidé de transmettre la responsabilité de construire, gérer et embarquer ffmpeg à Azur, le framework de Lephe dont MQ repose principalement pour ses opérations internes et graphiques.
Il faut donc bien prendre en compte que l'enregistreur vidéo présent dans les binaires d'MQ n'embarque PLUS le support des encodeurs hardware. Si vous avez explicitement besoin d'utiliser un encodeur hardware, vous devez lancer MQ et faire une demande dans record > load system > ffmpeg qui s’occupera d’aller charger codecs hardware présents sur votre système (mais c'est à vous de tout avoir installer en amont).
Parlons maintenant du second fautif : la différence entre Forgejo et Github.
Il est important de comprendre que les "actions" implémentées par l'équipe de Forgejo visent à supporter la grande majorité de ce que propose Github en termes de configuration. Cependant, beaucoup de dépendance et de mode de fonctionnement diffèrent suffisamment pour être assez casse-pieds à adapter (comme par exemple le fait d'uploader les binaires dans les releases qui demande des secrets particulièrement mal documentés). De plus, l'image Docker de base proposée par Forgejo embarque une version de GCC qui crash (littéralement) lors du linkage de MQ pour Linux.
C'est pourquoi, on a créé une image Docker custom avec la majorité des outils dedans (fxsdk, gint, sh-elf-gcc, ...). L'idée étant que lorsque l'on commencera la refonte de gint pour la v3, le fxsdk vous proposera une interface pour lancer votre CI en local qui vous permettra de faciliter la création des releases ainsi que le partage des projets! Ceci étant dit, on est bien loin d'en arriver là pour l'instant puisque la refonte de Gint, bien que prévue, n'est pas notre priorité pour cette année (spoiler plus bas).
Stabilité et compatibilité des addins mono
Comme énoncé dans l'introduction, le second gros point de cette release concerne la stabilisation de l'émulation des machines monochrome en corrigeant tout un tas de bogues qui trainaient, en améliorant l'expérience utilisateur et en implémentant les fonctionnalités qui manquait pour rendre (enfin) la majorité des applications utilisable!
Gestion du temps
Au cours de l'implémentation du Throttle, une fonctionnalité que l’on vous présentera juste après, 2 bugs majeurs ont été découverts dans le cœur de MQ concernant sa façon de gérer le temps qui passe. Comme l'explication reste assez technique, je vous fais une synthèse / résumé des bugs qu'on a corrigés.
Le premier bug concerne les pauses. Lorsqu'on demandait au thread d'émulation de patienter quelques secondes, le timer qui s'occupait de garder compte de "Où est-ce qu'on en est temporairement ?" continuait tranquillement de faire sa vie au lieu de se mettre en pause.
Le fait que ce timer continue de compter alors qu'on avait demandé à la machine de se mettre en pause, influence énormément les "background process" qui, eux, tournent constamment. Fatalement, une fois la machine réveillée, elle se retrouve a être “dans le passé” (ou en tout cas en décalage grave avec "le temps réel de la machine")! Ce qui causait tout un tas d'instabilités sur certains timings.
Deuxième bug qui a été corrigé avec la gestion du temps, c'est en lien avec le syscall Sleep(), qui.....bah ne dormait pas. Le syscall demande à l'OS (dans notre cas MQ) d'arrêter d'exécuter des instructions pendant X millisecondes. Et MQ indiquait bien au thread d'émulation "salut, on va attendre X millisecondes", ce à quoi le thread répondait "oui t'inquiète..."... puis continuait sa vie et l'exécution d'instructions comme si de rien n'était...
Enfin bref, c'est pour toutes ces raisons que les addins monochrome étaient majoritairement cassés : on ne supportait tout simplement pas les demandes de pause (alors que supporter avec une précision absurde des fonctionnalités hardware obscures de l'horloge temps-réel (RTC) oui). On a donc corrigé le support des demandes de pause et tout s'est mis à fonctionner comme par magie!
Quoi qu'il en soit, on a prévu une grosse refonte concernant cette partie pour avoir un temps déterminé à l'avenir. Ce qui sera extrêmement pratique pour déboguer vos programmes, mais surtout pour exporter toutes vos actions avec la machine virtuelle. Ce qui vous permettra de "rejouer" vos actions lors d'un reset pour vous éviter de refaire indéfiniment les mêmes opérations pour chasser un bug.....ou pour faire du TAS sur vos jeux favoris 👁️
Throttle
C'est une brique que l'on jugeait essentielle jusqu'à la découverte récente des deux bugs de gestion du temps, car ce système permet tout simplement de limiter la vitesse de l'émulation a un nombre de FPS fixe, ce qui est extrêmement pratique avec certains jeux qui repose soit principalement sur la "lenteur" de la machine ou soit ont simplement de grosse variation de FPS comme le FlappyBird de Lancelot.
A noter que ce système reste assez expérimental, car nous n'avons aucun moyen simple de savoir quand est-ce qu'un nouveau “frame” a été généré (puisque les addin écrivent directement à l'écran, n'importe où et n'importe quand). Pour pallier ce manque d'information, nous sommes partis du principe que, dans 99% du temps, les applications finissent leur frame en écrivant le pixel en bas à droite de l’écran. Donc si on détecte une écriture à ce pixel précis, on indique qu'un nouveau frame vient d'être fini et on applique le throttle.
Vous pouvez jouer avec le throttle dans le menu Performence > Thottle !
Getkey
Beaucoup de jeux mono étaient bloqués ou partiellement jouables, car ils reposaient sur le syscall bien connu : Getkey(). On n'avait jamais pris le temps de l'implémenter, car il est astralement immense et fortement enclavée dans l'OS. Par exemple, il peut afficher des trucs à l'écran, changer de processus (entre l'application et le menu), changer la luminosité, ... sans parler du comportement absolument exotique de la fonction qui la rend absolument horrible à implémenter, même partiellement.
Enfin bon, Lephe a fait face au monstre et a implémenté une version non complète, mais fonctionnelle du getkey(), ce qui a permis à beaucoup de jeux d'être enfin jouables ! Au passage, Lephe a fait un gros détour pour implémenter une partie du cœur des syscalls de dessins qui sont relativement communes entre calculatrices monochrome et couleur, ce qui va permettre de supporter rapidement (au besoin) beaucoup de syscalls gratuitement !
Bfile!
Le support de Bfile(), qui permet de manipuler les fichiers, manquait cruellement a MQ.
Le support a mis du temps à être mis en place pour la simple et bonne raison que l'on voulait originellement simuler le rendu de la mémoire de stockage (Flash/ROM) comme elle est représentée sur la vraie machine, ce qui nous permettrait de supporter les addin "avancée" qui ne passent pas par Bfile pour lire les fichiers mais directement par la mémoire (e.g. cgDoom).
Cependant, comme depuis un moment on vous dit qu'on aimerait passer a autre chose et voyant beaucoup de demande pour le support de Bfile, on a implémenté une version basique qui s'interface avec votre OS via toutes les operations commune (open(), read(), write(), ...), rendant le support fonctionnel pour une grande majorité des addins.
Ceci étant dit, l'implémentation qu'on avait originellement en tête devra être implémentée à l'avenir puisqu'on a "récemment" réussi avec Lephe à réimplémenter Fugue sans passer par Bfile() (ce qui donne de très très bonnes performances)...... Cette fonctionnalité sera intégrée à Gint3 plus tard, mais repose exclusivement sur l'analyse de la ROM (pas supportée actuellement donc).
Sliding!
Un autre point, moins utile, mais toujours classe : le support du slide sur le clavier. Cette fonctionnalité était surtout utilisée par FruitNinja et une version custom de 2048. Avec cette modification mineure côté GUI, on peut maintenant jouer à ces jeux de manière peu pratique (sauf si vous avez un écran tactile, là c'est exceptionnel)!
Un grand merci à Drakalex007 qui nous avait déjà fait part de cette fonctionnalité il y a quelques mois!
Graph 35+E II
Jusqu'à récemment, les addins patchés pour tourner sur la Graph 35+E II n'étaient pas supportés, et ce pour la simple et bonne raison qu'on n'avait jamais implémenté le driver ML9801 (le "nouvel" écran des calculatrices mono).
Le truc un peu subtil, c'est que contrairement aux calculatrices couleurs et les classpad qui ont des addins bien spécifiques ("g3a" et "hh2/hh3") qui permettent de savoir quel "driver" on utilise en interne dans MQ, les andin mono "g1a" ne permettent pas de savoir à l'avance si la machine utilise le T6K11 (l'écran historique) ou le nouveau ML9801. Il existe cependant plusieurs stratégies adoptées par les addins mono pour être portables:
Dans tous ces scénarios, MQ était gagnant car on pouvait forcer le driver T6K11 ni vu, ni connu. Cependant, on a découvert un nouveau type d'add-in assez rare, mais suffisamment présent pour casser MQ : les add-ins qui supportent uniquement le ML9801.
Ce n'est pas commun parce que le driver est assez "nouveau", très peu d'implémentations du driver existant à ma connaissance en dehors de gint et personne n'a encore fait d'application uniquement pour la Graph 35+E II...sauf certains vieux projets qui ont été patchés pour les rendre compatibles Graph 35+E II en remplaçant le driver T6K11 par celui du ML9801, les rendant donc utilisables uniquement sur le nouvel écran !
On a donc modifié un peu notre implémentation du driver T6K11 pour détecter si l'addin tente de communiquer avec le ML9801 et du coup supporter les quelques différences d'utilisation entre les deux écrans. Et maintenant, tous les programmes spécifiques Graph 35+E II sont fonctionnels !
UX
Une passe a aussi été faite pour améliorer l'expérience utilisateur avec MQ.
Sélection de dossier
Jusqu'à très récemment, la liste des programmes qu'MQ pouvait lancer (menu Control) était hardcodée au dossier où vous vous trouviez quand vous lancez l'émulateur. De plus, si le dossier courant avait des fichiers qui apparaissent ou disparaissaient, la liste n'était jamais mise à jour, il fallait redémarrer le programme.
Maintenant, vous pouvez sélectionner et/ou changer le dossier de sélection d'Addin depuis la GUI ou via l'option --dir ou -d lors de l'invocation de MQ. Par défaut, c'est toujours le dossier courant qui est sélectionné et MQ ne sauvegarde pas (encore) vos configurations entre vos sessions, mais cela sera implémenté dans de futures mises à jour.
Reset
Un bouton de “restart” a aussi été ajouté en plus d'une combinaison de touches (CTRL+R) pour redémarrer l'application actuellement en train d'être émulé. C'est pratique pour déboguer des applications sans avoir à re-sélectionner l'add-in dans la liste.
Next Frame
En profitant de la mise en place du throttle et de sa détection automatique de fin de frame, on a ajouté un bouton dans Control > cycles qui vous permet de demander l'émulation du programme jusqu'au prochain frame. C'est extrêmement pratique pour déboguer le visuel.
Enregistrement vidéo matériel
Comme mentionné au début de ce post, Lephe a récemment ajouté la possibilité de charger dynamiquement les codecs hardware qui sont installés sur votre machine.
Lors de la release précédente, MQ attendait implicitement que ffmpeg et toute sa clique (avutils, avcodec, ...) soient présents sur le système. Ce qui n'est honnêtement pas garanti au vu de toutes les versions différentes de l'outil et que beaucoup des sous-libraries demandent d'être installées manuellement...Bref, c'était extrêmement peu pratique, contraignant et bloquant pour beaucoup de personnes.
Nous avons fait le choix, comme expliqué plus haut, de faire bouger la responsabilité de cette grosse librairie à Azur, qui fournit maintenant une "abstraction" pour ffmpeg (voyez ça comme un pont) et embarque par défaut uniquement les encodeurs software.
Lors du démarrage de MQ, Azur va tenter de voir si vous avez un ffmpeg compatible d’installé sur votre machine. Si c’est le cas, alors elle sera utilisée à la place de celle embarquée par Azur et vous pouvez tenter de charger les codec hardwares en allant dans record > load system > ffmpeg.
Plus de compilation bloquante, plus de contrainte technique compliquée pour enregistrer vos parties endiablées de Gravity Duck.
Compatibilité et README
Après toutes ces modifications, nous sommes repassés sur la table des compatibilités, car cela faisait un bon moment qu'on ne l'avait pas fait. J'en ai aussi profité pour réécrire (...bientôt) une partie du README histoire de vendre plus de rêve maintenant qu'on peut faire du recording et avoir des vraies vidéos de démo.
A noter qu'on a récemment réussi à avoir plus de 50% des addins testés en fonctionnel !
Suite
Quand est-il de la suite ?
Concernant Lephe et moi-même, on a eu des changements dans la vraie vie véritable qui nous ont grandement réduit nos fenêtres de progression sur nos projets. Rien de grave, simplement Lephe a déménagé à Rennes et a beaucoup de papiers, de travail et de candidatures à faire et moi j'ai (enfin) réussi à trouver du travail en tant qu'Accompagnateur Pédagogique dans une école à Lyon...mais 80% des effectifs ont été supprimés donc on se retrouve un peu sous l'eau.
Bref, tout ça pour dire que, fatalement, on a beaucoup moins de bande passante qu'avant. Ceci étant dit, avec Lephe, on est assez contents et fiers du résultat actuel de MQ et c'est pourquoi, comme teasé depuis plusieurs Progress Report, on va laisser ce projet de côté pour se tourner vers l'un des objectifs principaux de cette année : La v5 de Planète Casio.
On vous tiendra au courant des avancées!
A plus!
Citer : Posté le 07/04/2026 21:36 | #
C'est du super boulot.
C'est cool d'avoir le support du système de fichier.
J'ai pu essayer sur NppClone et fxcgRPG,il y a plein de trucs qui fonctionnent vraiment bien, encore qq petits syscalls inconnus, mais c'est vraiment utilisable.
Merci beaucoup pour le super taf !! Ca va vraiment aider à dev sur les machines Casio, et aussi à conserver le patrimoine vidéo ludique !!
Citer : Posté le 09/04/2026 21:00 | #
This looks interesting. Is it possible to select the type of calculator and hardware? For example on the CG side: Math+/CG100 vs CG50, and on the FX side: 9860G vs Slim vs 9860GII vs GIII (SH4)? This could be really useful in testing my add-ins on calculators that I don't own.
Citer : Posté le 09/04/2026 21:14 | #
We intend to have such features in the future, but for now there's just a default fx-9860G II for mono (although the G-III screen is recognized) and an fx-CG 50 for the Prizms.