|
Tutoriel rédigé le : 2020-12-20 21:47 par Lephenixnoir Catégorie : Tutoriels du Mercredi Calculatrice : Toutes
Discutez de ce tutoriel sur le forum >> Voir le sujet dédié (17 commentaires)
TDM 18 : Comprendre les données et leurs représentations
Le Tutoriel du Mercredi (TDM) est une idée proposée par Ne0tux, qui recouvre tous les usages de la calculatrice - des applications de Casio à la conception de jeux en passant par la production artistique.
Aujourd'hui, on explore la notion de données dans les add-ins !
Ce tutoriel fait partie des publications de l'Avent 2020.
Niveau ★ ★ ★ ☆ ☆ (Lycée/Terminale selon les parties)
Tags : Données, Conversion, Représentation, C
Bienvenue dans ce tutoriel ! Si vous vous êtes déjà demandé « comment convertir un fichier en binaire ? », avez essayé d'afficher un entier avec Print(), de convertir un fichier g1a en g1m, ou n'arrivez simplement pas à mettre le doigt sur ce à quoi sert l'hexadécimal, vous êtes au bon endroit. 
Aujourd'hui, on va parler de ce que sont les données, de ce qui est (et n'est pas) une conversion, et aborder en même temps les questions de formats de données et de fichiers. Ce sont des choses que les langages de programmation essaient de cacher la plupart du temps parce qu'on a rarement besoin de s'en soucier, donc quand ce moment arrive il est facile d'être perdu.
Ce tutoriel vous aidera à comprendre ce qui se cache vraiment derrière vos variables, images et fichiers, et à distinguer les changements de représentation des conversions. Vous verrez qu'en C en particulier il y a quelques subtilités !
Sommaire
• Les données numériques : que des 0 et des 1
• Grouper pour mieux régner : la représentation hexadécimale
• Entiers en base 2 et en base 16
• Types de données : une variété de tailles et de rôles
• Interprétation des données : pourquoi on type les variables et les fichiers
• Représentation des données : comment afficher ses variables
• Conversions : ce qui en est et ce qui n'en est pas
• Les conversions impossibles : ne pas se tromper sur le type
• Conclusion
Les données numériques : que des 0 et des 1
Dans un ordinateur, la nature des données est facile : tout est fait de 0 et de 1. Ce texte que vous lisez est fait de 0 et 1. Le score maximal que vous venez d'enregistrer dans votre jeu favori est fait de 0 et de 1. La musique que j'écoute, les pixels qui sont affichés sur votre écran, tous les fichiers présents sur nos disques durs... tout est fait de 0 et de 1.
La raison pour ça est simple : un ordinateur fonctionne avec des signaux de tension électrique, et plus il y a de valeurs différentes plus le risque que le circuit électronique transforme une valeur en une autre par un phénomène physique est élevé. Dans une puce où le 0 est représenté par une tension de 0 V et le 1 est représenté par une tension de 3.3 V (par exemple), on arrive à s'en sortir et à éviter que les 0 ne se changent en 1 juste parce que du courant fuite ou parce qu'un champ magnétique autour du processeur modifie le fonctionnement du circuit.
Vous savez certainement qu'on appelle ça le système binaire, et que chaque 0 ou 1 est appelé un bit. Si vous dites « données numériques » ou « données binaires » ça revient au même : une longue liste de bits. La première chose que vous pouvez retenir est donc que :
Retenez  Toutes les données qui existent dans un ordinateur sont binaires. « Convertir en binaire » est donc une notion un peu absurde, car l'objet que vous essayez de convertir est déjà en binaire. Toutes les données qui existent dans un ordinateur sont binaires. « Convertir en binaire » est donc une notion un peu absurde, car l'objet que vous essayez de convertir est déjà en binaire.
Grouper pour mieux régner : la représentation hexadécimale
Les bits c'est pratique pour un ordinateur, mais pas pour un humain. Les ordinateurs sont conçus pour différentier 0 V et 3.3 V, et c'est tout. Mais les humains sont capables de différencier bien plus que ça : par exemple quand on lit on est aisément capables de différencier 10 chiffres et 26 lettres. Par contre, on peut vite faire des erreurs de lecture, surtout s'il y a plein de chiffres qui se répètent. Par exemple, si je vous fais lire
10011010100010000000000111110001,
il est probable que vous ayez besoin de vous y reprendre à deux fois pour énoncer le bon nombre de 0 dans la longue séquence du milieu. Et vous serez incapable de répéter la séquence sans la lire une deuxième fois. Tandis que si je vous fais lire
9a8801f1,
vous allez le prononcer correctement du premier coup et vous pourrez peut-être même répéter la séquence sans la relire. Pour un humain, c'est beaucoup plus facile de lire, analyser et communiquer des données sous cette forme.
Le deuxième texte ci-dessus est la représentation hexadécimale de la chaîne de bits qui précédait. C'est juste une représentation parce que les données sont les mêmes, je les ai juste écrites différemment, avec une notation différente. En particulier, comme je n'ai pas changé les données il n'y a pas eu de conversion (on en reparle plus tard).
Comment est-ce que ça marche ? La représentation hexadécimale consiste à grouper les bits par 4 et à associer un caractère différent à chacune des 16 combinaisons possibles. La correspondance se fait comme ceci :

Et donc, si on reprend la donnée de tout à l'heure, on peut découper en paquets de 4 bits et remplacer chaque paquet par le caractère qui va bien.
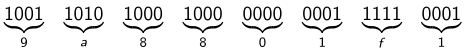
De la même façon, on peut repartir de la chaîne hexadécimale et re-développer en binaire pour récupérer les bits d'origine. On n'a fait que changer l'écriture, les données sont parfaitement intactes. Le format hexadécimal est simplement plus agréable à lire pour les humains.

Retenez L'hexadécimal est utilisé pour afficher des données binaire sous une forme compacte et facile à lire pour les humains.
Si vous faites un peu de programmation bas-niveau en C ou en assembleur, ou que vous décortiquez des fichiers exécutables, ou inspectez des fichiers dont vous ne connaissez pas le type, alors il y aura de l'hexadécimal partout. Parce que dans toutes ces situations il y a des données à représenter, et à défaut de mieux l'hexadécimal est utilisé pour vous les montrer, en espérant que ce sera agréable à lire pour vous.
Par exemple, si j'affiche le contenu du fichier texte dans lequel j'ai enregistré le texte de ce tutoriel avec l'outil Linux xxd, j'obtiens ce résultat.
00000000: 2320 5444 4d20 3138 203a 2043 6f6d 7072 # TDM 18 : Compr
00000010: 656e 6472 6520 6c65 7320 646f 6e6e c3a9 endre les donn..
00000020: 6573 2065 7420 6c65 7572 7320 7265 7072 es et leurs repr
00000030: c3a9 7365 6e74 6174 696f 6e73 0a0a 5b69 ..sentations..[i
00000040: 5d4c 6520 5475 746f 7269 656c 2064 7520 ]Le Tutoriel du
00000050: 4d65 7263 7265 6469 2028 5444 4d29 2065 Mercredi (TDM) e
00000060: 7374 2075 6e65 2069 64c3 a965 2070 726f st une id..e pro
00000070: 706f 73c3 a965 2070 6172 205b 7072 6f66 pos..e par [prof
00000080: 696c 5d4e 6530 7475 785b 2f70 726f 6669 il]Ne0tux[/profi
(...)
Si on ignore pour l'instant les colonnes de gauche et de droite, vous pouvez voir que xxd m'a affiché les bits de mon fichier, groupés par 4 en hexadécimal. Ainsi j'ai pu accéder à la donnée qu'est le texte de ce TDM. Et on va voir tout à l'heure que le résultat n'était pas facile à prédire, car il y a plein de façons d'associer une donnée binaire à un texte.
Entiers en base 2 et en base 16
Vous savez certainement que la spécialité des ordinateurs c'est le calcul, et le calcul ça commence par les entiers. Les ordinateurs ont donc leur propre méthode pour représenter des entiers avec des bits. Ce n'est qu'une des innombrables choses qu'on utilise quotidiennement sous forme binaire (texte, images, musiques, vidéos, programmes, nombres réels, et caetera), mais ils sont si importants qu'ils ont d'office leur place dans ce tutoriel.
Le principe pour écrire des nombres avec des bits est similaire à la façon dont on les écrit en décimal. En décimal, les chiffres des unités représente un nombre de « 1 » à ajouter au total, le chiffre des dizaines représente un nombre de « 10 » à ajouter au total, celui des centaines un nombre de « 100 »... et ainsi de suite. On peut donc décomposer un nombre sur ces puissances de 10 successives.
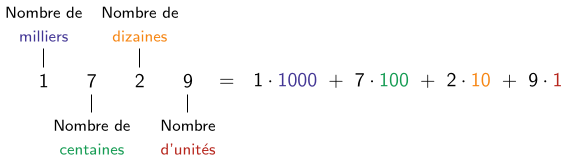
On peut faire pareil en base 2, mais pour que ça marche chaque bit doit représenter une puissance de 2 au lieu d'une puissance de 10. Ainsi le premier bit représente un nombre de « 1 » à ajouter un total, le suivant un nombre de « 2 », le troisième un nombre de « 4 »... et ainsi de suite. Voici un exemple.
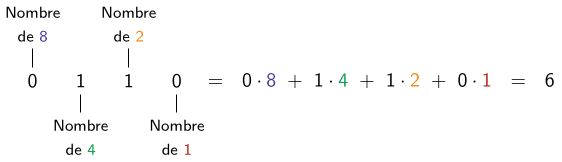
On peut prouver (ce n'est pas très difficile) que tous les nombres entiers peuvent s'écrire en base 2, et ce de façon unique. Autrement dit, il y a une correspondance complète entre les séquences de chiffres en base 10 et les séquences de chiffres (bits) en base 2. C'est très pratique parce que ça veut dire que si vous avez un nombre vous pouvez l'écrire en base 10 ou en base 2 selon le contexte, et il n'y a aucun risque d'ambiguïté.
Si tout ça vous paraît un peu confus, vous pouvez considérer cette analogie avec des images. Quand vous avez une image, vous pouvez l'enregistrer (entre autres) au format PNG ou au format BMP ; ces deux formats sont équivalents, car ils enregistrent fidèlement toutes les images. Le PNG est plus compact, mais le BMP est plus facile à coder. De la même façon, quand vous avez un entier, vous pouvez l'écrire en base 10 ou en base 2 ; ces deux bases sont équivalentes, car elles encodent fidèlement tous les entiers. La base 10 est plus naturelle pour les humains, mais la base 2 plus naturelle pour les machines.
Pour ne pas confondre 10 « dix » en décimal et 10 « un-zéro » en binaire (qui vaut deux), il est courant de mettre un préfixe devant les nombres écrits en binaire. En C/C++ (avec GCC), ce préfixe est « 0b » (zéro-b), et donc on écrit :
0b10 = 2, 0b0110 = 6, 0b11011000001 = 1729.
Quand il n'y a pas de préfixe on sous-entend que c'est en base 10.
Cette propriété qu'on peut écrire les nombres en base 10 et 2 n'est pas spécifique aux nombres 10 et 2 ; ça marche avec toutes les nombres. On peut aussi écrire les entiers de façon unique en base 7, ou les chiffres comptent pour 1, 7, 49... mais personne ne le fait parce que ce n'est naturel ni pour les humains ni pour les machines.
Cette nouvelle information permet de voir la représentation hexadécimale sous un autre angle. En effet, si vous regardez les séquences de 4 bits comme des nombres, vous pouvez voir que les caractères utilisés dans la représentation hexadécimale ne sont pas anodins :
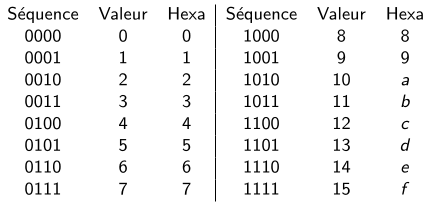
Les caractères de la représentation hexadécimale sont en fait 16 chiffres représentant les valeurs de 0 à 15. Le fait qu'on utilise des lettres ne doit pas vous tromper, car le principe est vraiment le même qu'avec les autres bases :
• En base 2, il y a 2 symboles représentant les valeurs de 0 à 1.
• En base 10, il y a 10 symboles représentant les valeurs de 0 à 9.
• En base 16, il y a 16 symboles représentant les valeurs de 0 à 15.
Maintenant qu'on a 16 symboles sous la main on peut écrire des nombres en base 16 exactement comme on les écrivait en base 10 et en base 2.

De la même façon qu'on utilie le préfixe 0b pour distinguer les nombres en base 2, on a le préfixe « 0x » (zéro-x) pour les nombres en base 16. On écrit donc :
0xf = 15, 0x100 = 256, 0x6c1 = 1729, 0x27f3 = 10227.
Comme on ne risque plus de confondre, on peut maintenant écrire sans se tromper le même nombre dans plusieurs bases :
0b11011000001 = 1729 = 0x6c1.
En général on écrit rarement les nombres en base 2 et beaucoup plus souvent en base 16, car :
• Tout comme la représentation hexadécimale, c'est plus compact et plus facile à lire pour les humains.
• On a rarement besoin de savoir quels bits précis sont dans un entier.
• L'hexadécimal est déjà utilisé pour afficher les données binaires, c'est pratique d'avoir un seul format.
Retenez Les ordinateurs écrivent leurs entiers en base 2 ; ils ne savent manipuler que des 0 et des 1 donc c'est le plus naturel pour eux.
Retenez Les humains écrivent leurs entiers en base 10 ou 16 ; la base 10 est très naturelle car on apprend à compter avec, et la base 16 ressemble à la base 2 mais en plus compact et lisible.
Interlude pour ceux qui veulent réfléchir.
J'ai expliqué dans cette section comment une séquence de bits peut être vue comme un entier écrit en base 2, et comment une séquence de caractères hexadécimaux peut être vue comme un entier en base 16.
J'ai aussi mentionné dans la section précédente qu'on peut passer d'une séquence de bits à une séquence de caractères hexadécimaux en groupant les bits par 4.
Vous noterez que dans l'exemple ci-dessus, si on groupe les bits de 11011000001 par quatre (en ajoutant un zéro à gauche pour obtenir un multiple de 4), on obtient la donnée 0110 1100 0001, dont la représentation hexadécimale est 6c1.
En fait si on écrit un entier en base 2, qu'on représente la séquence de bits sous sa forme hexadécimale, et qu'on tente de lire le résultat comme un entier écrit en base 16, on obtient l'entier d'origine (et pareil dans l'autre sens). Par exemple, si on regarde la première séquence mentionnée dans ce tutoriel :
0b10011010100010000000000111110001 = 2592604657 = 0x9a8801f1.
Ainsi, si on a des données qu'on pense être un entier, on peut calculer la valeur de cet entier peu importe si les données sont affichées en binaires ou en hexadécimal : le résultat sera le même. (Et ce n'est pas un hasard, c'était prévu depuis le début !)
Fin de l'interlude.
Types de données : une variété de tailles et de rôles
Jusqu'ici, on a vu que les ordinateurs ne travaillent qu'en binaire, et on a vu comment ils s'y prennent pour écrire des entiers en binaire. Cette façon d'écrire en base 2 était connue bien avant qu'on commence à s'en servir dans les machines et est tombée à pic quand l'électronique à commencé à se développer.
Entiers non signés de 8, 16, 32 et 64 bits
Mais il y a un petit défaut : tous les nombres ne prennent pas la même place à écrire. Certains nombres prennent 3 bits comme 0b101 = 5, tandis que d'autre ont besoin de 5 bits comme 0b10011 = 19. L'électronique du processeur ne peut pas se permettre de changer de taille d'une fois sur l'autre, donc les ingénieurs se sont mis d'accord pour utiliser une seule taille : 8 bits.
Tout comme les nombres sur 3 chiffres en décimal vont de 000 à 999, les nombres sur 8 bits en binaire vont de 0b00000000 à 0b11111111 = 255. L'intérêt de 8 bits c'est que ça correspond tout pile à 2 chiffres en hexadécimal, et donc ces nombres sur 8 bits correspondent tout pile aux nombres entre 0x00 et 0xff en hexa.
Ce format est devenu tellement courant qu'il a maintenant un nom : octet (ou byte en anglais). On appelle octet toute séquence de 8 bits, que cette séquence soit utilisée comme un entier ou non. Ce groupement a même influencé la façon dont la mémoire (par exemple la RAM) est conçue, si bien qu'en pratique on ne mesure jamais rien en nombre de bits, on mesure tout en nombre d'octets. À tel point que si une donnée occupe un nombre de bits qui n'est pas multiple de 8 on rajoute des 0 pour arrondir à l'octet supérieur !
Retenez L'archétype de l'entier est un entier non-signé sur 8 bits (1 octet), et peut représenter les nombres de 0 à 255.
Retenez L'octet est devenu tellement fondamental qu'on compte désormais tout en octets et non en bits.
Les processeurs passent énormement de temps à faire du calcul sur les entiers et ont tous une taille préférée. Ceux qui utilisent des entiers 8 bits dans leur calcul sont appelés aujourd'hui des processeurs 8-bit, ils appartiennent à une époque glorieuse (notamment marquée par l'icônique Intel 8086) mais révolue. Parce que comme vous pouvez vous en douter, compter jusqu'à 255 c'est marrant deux minutes mais ça ne nous emmène pas particulièrement loin. 
Les processeurs ont donc évolué et avec le temps se sont mis à calculer avec des entiers plus gros : d'abord 16 bits (2 octets), puis 32 bits (4 octets), puis 64 bits (8 octets). La raison pour laquelle on ne veut que des nombres d'octets qui sont des puissances de 2 est liée au fonctionnement de la mémoire, j'en parlerai sans doute dans le TDM 19 (celui-ci est déjà assez long !).
Retenez On trouve couramment des entiers de 16, 32 et 64 bits, chacun pouvant représenter une plage de valeur plus grande que les précédents.
En C, vous pouvez accéder à ces types sous les noms uint8_t, uint16_t, uint32_t et uint64_t. Ils sont définis dans l'en-tête <stdint.h> (standard integers).
#include <stdint.h>
uint8_t entier_8_bits = 145; // maximum = 255
uint16_t entier_16_bits = 28493; // maximum = 65535
uint32_t entier_32_bits = 92837483; // maximum = 4294967295
uint64_t entier_64_bits = 374392373438ull; // maximum = 18446744073709551615ull
Comme vous pouvez le voir, selon les usages différents types d'entiers peuvent être utilisés. Dans la plupart des situations, les entiers 32 bits suffisent, mais si vous voulez compter la population mondiale vous aurez besoin de 64 bits car il y a plus de 4 milliards d'invididus sur Terre. 
Vous noterez que ces valeurs maximales sont un peu ingrates à lire en décimal, mais beaucoup plus faciles à lire en hexadécimal :
• Le maximum d'un entier 08 bits est 0xff.
• Le maximum d'un entier 16 bits est 0xffff.
• Le maximum d'un entier 32 bits est 0xffffffff.
• Le maximum d'un entier 64 bits est 0xffffffffffffffff.
Si vous avez un nombre en hexadécimal il vous suffit donc de compter combien il a de chiffres pour savoir quels types entiers peuvent ou pas le représenter !
Entiers signés
Comme j'ai passé pas mal de temps sur les entiers déjà, je ne veux pas m'attarder ici. Mais sachez qu'il existe une technique pour représenter des nombres signés (positifs et négatifs) en binaire. On pourrait juste rajouter un bit pour dire si le signe est + ou -, mais c'est compliqué de calculer avec cette méthode. À la place, une technique appellée le complément à deux est utilisée presque partout.
La seule chose que vous avez besoin de savoir est que l'intervalle représentable par les entiers signés est réparti à moitié sur des nombres négatifs et sur des nombres positifs :
• Un entier signé sur 8 bits peut représenter de -128 à 127.
• Un entier signé sur 16 bits peut représenter de -32768 à 32767.
• Un entier signé sur 32 bits peut représenter de -2147483648 à 2147483647.
• Et ainsi de suite.
Ces types en C sont nommés int8_t, int16_t, int32_t et int64_t. Ils sont aussi accessibles dans <stdint.h>.
Vous remarquerez sans doute un schéma de nommage. u (unsigned) signifie que le nombre est non-signé, s'il n'y a pas de u on considère que le nombre est signé par défaut. int (integer) signifie « entier » en anglais, ensuite vous avez la taille en nombre de bits et le "_t" final est une convention pour dire que c'est un type (pour ne pas le confondre avec un nom de variable).
Une note sur les entiers standard : char, short, int et long
Vous ne connaissiez peut-être pas les types de <stdint.h>, et pensiez peut-être à des choses comme char, short, int ou long. Ce sont aussi des entiers, mais il n'est pas toujours facile de connaître leur taille.
Historiquement, int représente la taille d'entier préférée du processeur. Sur la calculatrice, qui utilise un SuperH 32-bits, c'est un entier de 32 bits. Mais sur le microcontrôleur qu'on trouve dans les Arduino, qui est un processeur 16 bits, c'est un entier de 16 bits. C'est d'ailleurs une erreur assez fourbe quand on programme sur une Arduino. Sur les EZ80 des calculatrices TI, qui est un processeur 8 bits, c'est un entier de 8 bits.
Quand les processeurs 64 bits sont arrivés, les gens ont jugé que peu de variables avaient besoin d'aller au-delà de la valeur limite sur 32 bits (plusieurs milliards !) et que ça ne valait pas le peine de doubler la mémoire que prennent les int juste pour ces cas-là. Du coup int est resté sur 32 bits, et c'est long qui représente les nombres de 64 bits. Mais tous les compilateurs et OS ne le font pas pareil... et du coup c'est juste un énorme bordel. Vous pouvez voir sur Wikipédia (en anglais) que selon le standard C, le type de processeur et l'OS utilisé la taille change, ce qui est vraiment pas pratique.
Mon conseil c'est de ne pas se casser la tête avec ça et :
• D'utiliser int quand on veut juste « un entier quelconque » et que la valeur maximale est de toute façon petite.
• D'utiliser les entiers de <stdint.h> quand on veut être sûr que l'entier peut représenter des grandes valeurs, ou qu'on veut un petit entier pour ne pas consommer trop de mémoire.
Le texte : ASCII et UTF-8, l'enfer passé sur les encodages
Profitons de cet instant pour faire un peu moins de maths et un peu plus de littérature. Comme toutes les choses qui existent dans le monde informatique, le texte est aussi représenté par des données binaires, et il faut donc un moyen d'associer une séquence de bits à une séquence de caractères.
Contrairement aux entiers où il y a beaucoup de contraintes (notamment celle que les additions et multiplications doivent être les plus efficaces possibles), pour le texte on peut faire un peu ce qu'on veut. Il suffit de choisir une séquence de bits pour chaque caractère qu'on veut pouvoir écrire, et tant qu'il n'y a pas d'ambiguïté ça marchera. On appelle ça un encodage de texte.
Dans les années 1960, les Américains ont inventé ASCII, un encodage qui dit quelle séquence de bits on associe à chacun de 128 caractères prédéfinis. Ce sont des caractères utilisés pour écrire du texte en anglais (évidemment), et c'est loin de convenir à tout le monde : il n'y a pas d'accents, pas d'alphabets non-latins, pas d'idéogrammes, et surtout pas d'emojis. À l'époque ça a fait un tôlée sur Twitter. 
ASCII est tellement la norme de toutes les normes que même les super vieux encodages que vous pouvez trouver sont compatibles avec (c'est-à-dire que les caractères qu'ASCII couvre sont représentés dans ces encodages comme dans ASCII).
À l'origine ASCII utilise 7 bits par caractères, mais dans le monde moderne de l'octet on rajoute un zéro pour en avoir 8. Ainsi, en ASCII la séquence de bits pour la lettre "t" est 01110100, celle pour "e" est 01100101, et celle pour "s" est 01110011. On encode donc le mot « test » par
"test" 01110100 01100101 01110011 01110100
Mais c'est pas très lisible, donc comme d'habitude on utilise de l'hexadécimal.
"test" 74 65 73 74
Et si j'enregistre "test" dans un fichier, que j'affiche ensuite avec xxd, j'obtiens précisément cette séquence !
00000000: 7465 7374 test
Retenez ASCII est un encodage fondamental utilisé pour l'alphabet latin et quelques caractères spéciaux, et absolument tout le monde s'y conforme.
C'est le bon moment pour revenir sur ce qu'affiche xxd dans sa troisième colonne. Pour rappel, voici le début de ce fichier affiché en hexadécimal :
00000000: 2320 5444 4d20 3138 203a 2043 6f6d 7072 # TDM 18 : Compr
00000010: 656e 6472 6520 6c65 7320 646f 6e6e c3a9 endre les donn..
00000020: 6573 2065 7420 6c65 7572 7320 7265 7072 es et leurs repr
00000030: c3a9 7365 6e74 6174 696f 6e73 0a0a 5b69 ..sentations..[i
00000040: 5d4c 6520 5475 746f 7269 656c 2064 7520 ]Le Tutoriel du
00000050: 4d65 7263 7265 6469 2028 5444 4d29 2065 Mercredi (TDM) e
00000060: 7374 2075 6e65 2069 64c3 a965 2070 726f st une id..e pro
00000070: 706f 73c3 a965 2070 6172 205b 7072 6f66 pos..e par [prof
00000080: 696c 5d4e 6530 7475 785b 2f70 726f 6669 il]Ne0tux[/profi
(...)
Sur chaque ligne il y a 32 caractères hexadécimaux, ce qui fait 16 octets (8 groupes de 2 octets). La troisième colonne affiche les caractères ASCII associés à chacun de ces 16 octets lorsqu'il y en a, et des points sinon. On peut y voir plein de choses, par exemple que le premier octet (0x23) est le caractères "#", que les fins de lignes sont représentées par l'octet 0x0a, et que les accents s'affichent comme des points puisqu'il n'y a pas d'accents en ASCII.
(La première ligne affiche juste la position dans le fichier en hexa, vous pouvez voir que ça commence à 0 et que ça augmente de 0x10 = 16 octets à chaque ligne. Le préfixe 0x est implicite ici, c'est un peu casse-pieds quand on débute mais avec l'habitude on devine au contexte que c'est en hexadécimal.)
Le fait qu'il y ait si peu de caractères dans l'encodage ASCII fait qu'au fil du temps de nombreuses personnes et entreprises ont inventé leur propres encodages pour ajouter des caractères. Avec tous les pays du monde et la concurrence en plus, il existe une quantité faramineuse d'encodages tous plus incompatibles entre eux les uns que les autres, et cette variété a longtemps été un enfer parce qu'afficher un fichier utilisant un certain encodage avec un autre encodage donne un résultat incorrect et souvent n'importe quoi.
Par exemple, mon fichier est encodé en UTF-8. En UTF-8, le « é » de « données » est représenté, comme vous pouvez le voir à la fin de la deuxième ligne affichée par xxd, par les deux octets c3 a9. (Il y a bien plus de 256 caractères dans UTF-8 et donc tous ne peuvent pas s'écrire sur un seul octet.)
Si vous ouvrez ce fichier en pensant qu'il est encodé en ISO-8859-1, un encodage très courant en Europe avant qu'UTF-8 ne devienne la norme, vous obtiendrez un résultat très différent. Dans cet encodage, c3 est le caractère « Ã » et a9 est le caractère « © ». Du fait, vous verrez à votre écran, non pas « données », mais
« données »
Et je suis certain que ça vous est tous arrivé au moins une fois. C'est extrêmement casse-pieds et ça a posé des problèmes pendant des années, jusqu'à ce que Unicode débarque et commence à associer des nombres à tous les caractères utiles à l'époque, et mette tout le monde d'accord en écrasant tous les autres encodages avec un énorme pouvoir de standardisation.
(J'ai mentionné Unicode et UTF-8 : ce n'est pas exactement la même chose, mais dans le cadre de ce tuto on va considérer que c'est pareil sinon on sera encore là demain soir !)
Aujourd'hui, on est enfin sauvés et quasiment l'intégralité du monde utilise des chaînes de caractères et des fichiers en UTF-8, et ce problème est en passe de disparaître entièrement. Si vous avez déjà lu le manifesto sur le site utf8everywhere.org (en anglais) vous comprenez sans doute à quel point c'est important.
Retenez UTF-8 est le seul encodage dont le monde a besoin en 2020 et il n'y aucune raison d'utiliser autre chose.
Soit dit en passant, Casio se moque complètement de tout ça et continue d'utiliser dans son OS un encodage de texte personnalisé, que la communauté appelle FONTCHARACTER, qui semble vaguement dérivé de l'encodage japonais Shift-JIS en voie de disparition et qui vous oblige à écrire Print("donne\xe6\x0as") au lieu de Print("données"). (gint supporte l'UTF-8, je dis ça je dis rien.  ) )
En C, le type char est utilisé pour représenter un caractère ASCII. C'est un type d'un octet, sur à peu près toutes les machines que vous pouvez imaginez c'est un entier signé sur 8 bits, la même chose donc que int8_t.
Vous pouvez désigner un caractère par son code ASCII, mais le langage C vous offre la possibilité de mettre un caractère entre deux apostrophes et le remplacera par la valeur correspondante.
char t = 0x74; // Le caractère "t"
char t = 't'; // Exactement pareil
Un char ne contient vraiment qu'un octet, donc si votre fichier source est encodé en UTF-8 (et il devrait l'être) vous ne pouvez pas écrire 'é' parce que ça prend deux octets (0xc3 suivi de 0xa9). Il y a des APIs standard pour faire ça en C (wide strings, multibyte) mais honnêtement c'est très casse-pieds à faire et j'espère que vous n'en aurez jamais besoin.
Une chaîne de caractères complète s'écrit entre guillemets et se termine par un octet de valeur zéro, qui indique la fin du texte (sinon on ne saurait pas où s'arrête la chaîne, ce qui est dommage). Par exemple, le mot "données" sera représenté en mémoire par la séquence d'octets :
"données" 64 6f 6e 6e c3 a9 73 00
Le type approprié pour obtenir ça est char * (si on oublie un instant les questions de lecture/écriture).
char *str = "données"; // en mémoire, la chaîne contient les 9 octets ci-dessus
Notez que le langage C n'impose pas un encodage, il prend vraiment les octets qui sont enregistrés entre les guillemets. Pour avoir du texte en UTF-8 dans votre programme il faut enregistrer votre fichier source en UTF-8.
Nombre flottants
En C, à peu près tous les types sont des entiers ou des pointeurs (on parlera de pointeurs dans le TDM 19). Les seuls autres types natifs sont les nombres flottants, un sujet qui mérite (et a) des livres entiers, et qu'on ne va pas du tout détailler ici.
Tout ce que vous avez besoin de savoir c'est que les nombres flottants permettent de représenter (plus ou moins bien) des nombres décimaux comme 0.25 et aussi des nombres extrêmement petits ou grands comme 0.5·10⁻⁸⁵ ou 2.7·10²⁴³. Après avoir été un bordel pendant longtemps (un peu comme le texte), les nombres flottants sont maintenant régis par l'IEEE 754, et il y en a principalement deux tailles :
• Les nombres flottants sur 32 bits (float en C), avec environ 6 décimales de précision
• Les nombres flottants sur 64 bits (double en C), avec environ 15 décimales de précision
Les deux marchent exactement pareil, tout ce qui change c'est que le double a plus de décimales et peut aller encore plus loin dans l'échelle du minuscule et du gigantesque.
Voilà qui conclut une présentation (somme toute rapide) des types de données qu'on manipule tous les jours dans les programmes et en particulier dans les add-ins.
Interprétation des données : pourquoi on type les variables et les fichiers
Avec tout ce qu'on a vu avant, pouvez-vous me dire maintenant ce que ces 4 octets sont ?
70 50 32 3f
Prenez le temps de réfléchir, voire même de relire les paragraphes précédents.
...
La bonne réponse est « non ». On ne peut pas dire ce que sont ces 4 octets, car on ne sait pas si ce sont :
• Les quatre caractères ASCII 0x70, 0x50, 0x32 et 0x3f, c'est-à-dire "p", "P", "2" et "?"
• L'entier non signé de 32 bits 1884303935
• Les deux entiers non signés de 16 bits 28752 et 12863
• Les quatre entiers signés de 8 bits 112, 80, 50, et 63
• Le nombre flottant de 32 bits 0.696540
Et c'est parce que toutes ces choses, dans la mémoire, sont représentées par les quatre octets 70 50 32 3f. Et c'est là un problème fondamental qu'il est important de toujours garder en tête :
Retenez Toute donnée n'est utilisable que si vous connaissez son type/format.
Le langage C vous oblige à indiquer le type de vos variables spécifiquement pour vous éviter de vous mélanger les pinceaux, et d'écrire un float quelque part dans la mémoire pour le relire plus tard comme un uint32_t par erreur. Parce que la mémoire s'en moque, elle vous donnera les octets, et votre programme continuera de fonctionner avec une valeur absurde.
Ce problème est encore plus important avec les fichiers. Autant vous pouvez avoir un float raisonnable dont les octets représentent également un int raisonnable, autant les octets d'une image PNG ne représenteront jamais une image JPG. Prendre l'un pour l'autre c'est un échec garanti.
C'est pour cette raison qu'on met des extensions sur les fichiers. Le image.jpg c'est un peu comme int n, c'est la combinaison d'un nom et d'un type, permettant à l'utilisateur de l'image (que ce soit un logiciel ou un humain) de savoir comment il faut lire et utiliser les octets du fichier.
Généralement les formats de fichiers sont encore plus prudents que ça et contiennent des signatures qui les identifient. Par exemple, les premiers octets d'un fichier PNG contiennent une signature qui utilise les trois caractères ASCII 0x50, 0x4e et 0x47 ("P", "N" et "G"). Et le premier octet, 0x89, est invalide à cette position à la fois en ASCII et en UTF-8, pour éviter que l'image soit prise par erreur pour un fichier texte. Le résultat c'est que quand vous avez en face de vous un fichier d'un type inconnu vous pouvez quand même détecter son type la plupart du temps (l'utilitaire file fait ça sous Linux).
00000000: 8950 4e47 0d0a 1a0a 0000 000d 4948 4452 .PNG........IHDR
(...)
Les images sont des gros fichiers, généralement plusieurs milliers d'octets, donc on peut se permettre de consommer un peu de place pour mettre une signature. Mais dans un programme C où les variables sont des multitudes de petits objets, on n'a pas la place de noter leurs types en plus de leur valeur, et pas non plus le temps de vérifier à chaque utilisation que les types sont corrects. Il faut donc faire attention à ne pas lire des octets dans le mauvais type (ce qu'on appelle parfois du type punning).
Représentation des données : comment afficher ses variables
Maintenant qu'on a vu la différence entre les entiers et le texte, vous comprenez peut-être pourquoi il est impossible d'afficher un entier avec Print(), une fonction qui attend une chaîne de caractères.
En effet, si vous avec un int (de 4 octets) contenant la valeur 1729, ce que vous avez ce sont les quatre octets
00 00 06 c1
Mais pour afficher à l'écran vous avez besoin du texte "1729", qui contient les quatre caractères ASCII « 1 » (0x31), « 7 » (0x37), « 2 » (0x32) et « 9 » (0x39), plus un octet de valeur zéro à la fin pour signaler la fin de la chaîne. C'est-à-dire
31 37 32 39 00
Comme vous pouvez le voir c'est totalement différent. Non seulement ce ne sont pas les mêmes octets, mais en plus ce n'est même pas la même taille !
Obtenir le texte à partir de l'entier est donc une action non triviale qui requiert non seulement de décomposer le nombre en base 10 (ce qui nécessite de faire des multiplications et divisions par des puissances de 10) mais aussi de générer la bonne séquence de caractères ASCII. Ce genre de choses n'est pas automatique, et il faut bien que quelqu'un s'en charge.
Dans les langages plus haut niveau comme Python ou C++, la fonction print() ou l'opérateur << possèdent du code qui est appelé automatiquement si vous passez un entier en argument pour faire ce calcul. Mais en C, ce n'est pas automatique, et il faut utiliser une fonction de la famille de printf().
Il en va de même pour les flottants, en plus compliqué encore. Le problème avec les flottants c'est que contrairement aux entiers les nombres à virgule qu'on peut écrire en base 2 et en base 10 ne sont pas les mêmes. Et donc il y a des approximations et des ambiguïtés partout, et il faut faire excessivement attention tout le temps !
Conversions : ce qui en est et ce qui n'en est pas
Il y a beaucoup de vocabulaire dans cet article, et tous les termes n'ont pas forcément une définition spécifique, mais une chose est sûre : le terme « conversion » est souvent mal utilisé pour différentes raisons.
La question de la conversion vient du fait que les informations peuvent s'écrire de multiples façons. Par exemple, l'entier 1729 peut être écrit en binaire sur 16, 32 ou 64 bits (pas sur 8 car il est plus grand que 255). Il peut aussi être écrit sous forme du texte en base 10 "1729", du texte en base 16 "0x6c1", et bien d'autres façons encore.
Représentation ou encodage d'une information abstraite
Quand le sujet sur lequel on se concentre est une information abstraite, comme « l'entier 1729 », on dit généralement qu'on peut le représenter ou l'encoder dans différents formats. Les représentations de 1729 sont :
• Comme un nombre de 16 bits : 06 c1
• Comme un nombre de 32 bits : 00 00 06 c1
• Comme texte en base 10 : "1729" (dont les octets en ASCII sont 31 37 32 39 00)
• Comme texte en base 2 : "0b11011000001" (là je détaille pas les octets)
• Comme un nombre flottant sur 32 bits : 00 20 d8 44
De même, les encodages du mot « données » sont :
• En ASCII, rien du tout car l'ASCII ne peut pas représenter « é »
• En ISO-8859-1, 64 6f 6e 6e e9 65 73
• En UTF-8, 64 6f 6e 6e c3 a9 65 73
Retenez On représente une information par une séquence de bits.
Interprétation ou décodage d'une donnée
L'opération inverse consiste à prendre une donnée et à récupérer l'information abstraite. On parle d'interpréter ou de décoder la donnée. Comme on l'a vu, les interprétations de 70 50 32 3f sont :
• Comme texte ASCII, la séquence "pP2?"
• Comme entier non signé de 32 bits, 1884303935
• Comme nombre flottant de 32 bits, 0.696540
• (etc, il y en a bien d'autres)
Pour accéder à l'information il faut connaître le type de la donnée.
Retenez On interprète une séquence de bits pour récupérer l'information.
Conversion entre différents formats
Lorsque le sujet est une donnée (représentant une information) et qu'on veut obtenir une autre représentation de cette information, on peut parler de conversion de la donnée. Par exemple, l'information « entier 1729 » peut être représenté à la fois comme un entier 16 bis et comme un entier 32 bits, et la conversion du premier format au second transforme la donnée ainsi :
06 c1 → 00 00 06 c1
Les octets ont changé, on a donc converti la donnée tout en continuant de représenter la même information. De même, 1729 peut être représenté par un nombre flottant sur 32 bits, et la conversion d'entier 16 bits vers flottant 32 bits transforme la donnée ainsi :
06 c1 → 00 20 d8 44
Cette fois-ci la donnée n'a plus rien à voir mais l'information est préservée : c'est toujours 1729.
Comme ISO-8859-1 est un encodage vieux et que personne n'en veut plus, on veut convertir notre fichier texte contenant le mot « données » de l'encodage ISO-8859-1 à l'encodage UTF-8, qui est le seul encodage qui mérite encore d'exister en 2020. La donnée est transformée ainsi :
64 6f 6e 6e e9 65 73 → 64 6f 6e 6e c3 a9 65 73
Pas les mêmes bits, mais toujours le même mot.
C'est exactement pareil si vous convertissez une image BMP en PNG : pas le même fichier à la sortie, mais c'est la même image qu'avant. Vous voyez le motif ?
Retenez On convertit entre elles plusieurs représentations d'une même information.
Les conversions impossibles : ne pas se tromper sur le type
Même si ma définition reste heuristique, l'idée générale d'une conversion est de conserver l'information abstraite tout en changeant simplement le format qui la représente.
Mais cela n'est possible que si le format de départ et le format d'arrivée sont tous les deux capables de représenter l'information dont il est question. Par exemple, on ne peut pas convertir une image PNG en fichier texte, puisque l'information représentée par le fichier de départ (une image) n'est pas de même nature que l'information représentée par le fichier souhaite à l'arrivée (du texte).
De la même façon, on ne peut pas convertir un fichier g1a en fichier g1m car l'information dans le fichier de départ (du code exécutable et des données pour un add-in) n'est pas de même nature que ce que le fichier souhaité peut représenter (des fichiers résidant dans la mémoire principale).
Retenez On ne peut convertir des données que si elles représentent la même information.
De façon plus subtile, le terme de « conversion » a l'effet fourbe de nous faire croire qu'on peut transformer l'information dans les deux sens, alors que ce n'est pas toujours le cas.
Par exemple, si je réencode une image PNG au format JPG, la compression JPG va détruire une partie de l'information et ma nouvelle image sera subtilement différente de l'originale. Aucune transformation ne permettra de récupérer l'information perdue. Si on veut être vraiment rigoureux ce n'est donc qu'à moitié une conversion.
De la même façon, on peut convertir un nombre flottant en entier, mais on perd à la fois les décimales et la précision. Par exemple si j'écris int n = 1.47, le compilateur va automatiquement appeler du code pour convertir 1.47 (un double) en entier. Le résultat sera 1, et les décimales seront là aussi perdues.
Attention donc à ce que votre information devient quand vous planifiez de convertir une donnée !
Conclusion
Que ce soit dans les variables d'un programme ou dans les fichiers de votre ordinateur, des données de différents types se promènent partout dans le monde informatique.
Comprendre comment ces données sont écrites en binaire démontre pourquoi il est important de bien garder en tête quelle information on stocke et quelle représentation on utilise.
Une approche un peu rigoureuse du problème permet de mieux cerner les abus de notions intuitives comme celle de « conversion » et d'avoir un regard plus précis sur ce qu'on fait vraiment quand on manipule des données.
J'espère que ce (long) tutoriel vous aura appris quelque chose. J'ai pris beaucoup de plaisir à l'écrire, mais dans toute son imperfection il ne pourrait que profiter d'un commentaire ou d'une correction de votre part. N'hésite pas à en laisser dans les commentaires ! o/
Et à bientôt sur Planète Casio !
Consulter le TDM précédent : TDM 17 : Des images sur votre 90+E !
Consulter l'ensemble des TDM
Discutez de ce tutoriel sur le forum >> Voir le sujet dédié (17 commentaires)
|
|