gint : un noyau pour développer des add-ins
Posté le 20/02/2015 17:30
 Ce topic fait partie de la série de topics du fxSDK.
Ce topic fait partie de la série de topics du fxSDK.
En plus des options de programmation intégrée comme le Basic Casio ou Python, la plupart des calculatrices Casio supportent des
add-ins, des programmes natifs très polyvalents avec d'excellentes performances. Les add-ins sont généralement programmés en C/C++ avec l'aide d'un ensemble d'outils appelé SDK.
Plusieurs SDK ont été utilisés par la communauté avec le temps. D'abord le
fx-9860G SDK de Casio avec fxlib pour Graph monochromes (plus maintenu depuis longtemps). Puis le
PrizmSDK avec libfxcg pour Prizm et Graph 90+E (encore un peu actif sur Cemetech). Et plus récemment celui que je maintiens, le
fxSDK, dont gint est le composant principal.
gint est un unikernel, ce qui veut dire qu'il embarque essentiellement un OS indépendant dans les add-ins au lieu d'utiliser les fonctions de l'OS de Casio. Ça lui permet beaucoup de finesse sur le contrôle du matériel, notamment la mémoire, le clavier, l'écran et les horloges ; mais aussi de meilleures performances sur le dessin, les drivers et la gestion des interruptions, plus des choses entièrement nouvelles comme le moteur de gris sur Graph monochromes.

Les sources de gint sont sur la forge de Planète Casio :
dépôt Gitea Lephenixnoir/gint
Aperçu des fonctionnalités
Les fonctionnalités phares de gint (avec le fxSDK) incluent :
- Toutes vos images et polices converties automatiquement depuis le PNG, sans code à copier (via fxconv)
- Un contrôle détaillé du clavier, avec un GetKey() personnalisable et un système d'événements à la SDL
- Une bibliothèque standard C plus fournie que celle de Casio (voir fxlibc), et la majorité de la bibliothèque C++
- Plein de raccourcis pratiques, comme pour afficher la valeur d'une variable : dprint(1,1,"x=%d",x)
- Des fonctions de dessin, d'images et de texte optimisées à la main et super rapides, surtout sur Graph 90+E
- Des timers très précis (60 ns / 30 µs selon les cas, au lieu des 25 ms de l'OS), indispensables pour les jeux
- Captures d'écran et capture vidéo des add-ins par USB, en temps réel (via fxlink)
Avec quelques mentions spéciales sur les Graph monochromes :

Un moteur de gris pour faire des jeux en 4 couleurs !
La compatibilité SH3, SH4 et Graph 35+E II, avec un seul fichier g1a
Une API Unix/POSIX et standard C pour accéder au système de fichiers (Graph 35+E II seulement)
Et quelques mentions spéciales sur les Graph 90+E :

Une nouvelle police de texte, plus lisible et économe en espace
Le dessin en plein écran, sans les bordures blanches et la barre de statut !
Un driver écran capable de triple-buffering
Une API Unix/POSIX et standard C pour accéder au système de fichiers
Galerie d'add-ins et de photos
Voici quelques photos et add-ins réalisés avec gint au cours des années !


Arena (2016) — Plague (2021)
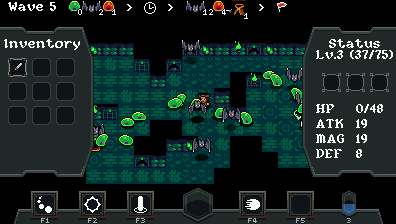
Rogue Life (2021)
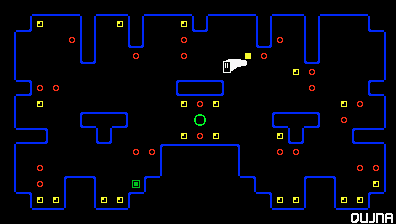
Momento (2021)
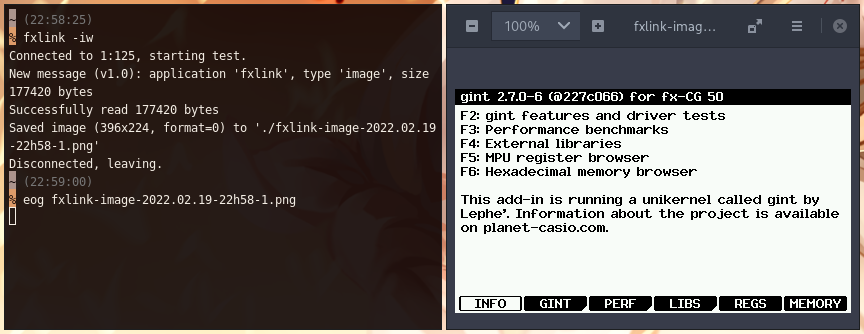
Communication avec le PC (cliquez pour agrandir)
Utiliser gint pour développer des add-ins
Les instructions pour installer et utiliser gint sont données dans les divers tutoriels recensés dans le
topic du fxSDK. Il y a différentes méthodes de la plus automatique (GiteaPC) à la plus manuelle (compilation/installation de chaque dépôt). Le fxSDK est compatible avec Linux, Mac OS, et marche aussi sous Windows avec l'aide de WSL, donc normalement tout le monde est couvert

Notez en particulier qu'il y a des
tutoriels de développement qui couvrent les bases ; tout le reste est expliqué dans les en-têtes (fichiers
.h) de la bibliothèque que vous pouvez
consulter en ligne, ou dans les ajouts aux changelogs ci-dessous.
 Changelog et informations techniques
Changelog et informations techniques
Pour tester les fonctionnalités et la compatibilité de gint, j'utilise un add-in de test appelé gintctl (
dépôt Gitea Lephenixnoir/gintctl). Il contient aussi une poignée d'utilitaires d'ordre général.
Ci-dessous se trouve la liste des posts indiquant les nouvelles versions de gint, et des liens vers des instructions/tutoriels supplémentaires qui accompagnent ces versions.
Anecdotes et bugs pétés
Ô amateurs de bas niveau, j'espère que vous ne tomberez pas dans les mêmes pièges que moi.
TODO list pour les prochaines versions (2023-04-03)
gint 2.11
- Changements de contextes CPU. À reprendre du prototype de threading de Yatis pour permettre l'implémentation d'un véritable ordonnanceur. Demandé par si pour faire du threading Java.
- Applications USB. Ajouter le support de descripteurs de fichiers USB. Potentiellement pousser jusqu'à avoir GDB pour debugger.
- Support de scanf() dans la fxlibc. Codé par SlyVTT, plus qu'à nettoyer et fusionner.
Non classé
- Regarder du côté serial (plus facile que l'USB) pour la communication inter-calculatrices (multijoueur) et ultimement l'audio (libsnd de TSWilliamson).
- Un système pour recompiler des add-ins mono sur la Graph 90+E avec une adaptation automatique.
- Support des fichiers en RAM pour pouvoir utiliser l'API haut-niveau sur tous les modèles et éviter la lenteur de BFile à l'écriture quand on a assez de RAM.


Citer : Posté le 06/08/2019 16:19 | # | Fichier joint
Fichier joint
Du côté de fxconv tout est bon, il ne supprime pas de ligne ou de colonne tant que tu ne spécifies un area sur la ligne de commande. Je viens de tester avec ton image, la première colonne est bien là.
Ce que tu décris doit marcher tout seul, c'était bien un bug dans l'algo de tracé ! (Un bug que j'avais déjà vu mais pas corrigé totalement, con comme je suis...) J'ai corrigé et poussé, Je te joins un g1a qui démontre le code fonctionnel ci-dessous et trace chaque élément de ton image indépendamment.
Merci de ta patience avec mon code encore jeune...
#include <gint/keyboard.h>
int main(void)
{
dclear(C_WHITE);
dtext(0, 0, "Sample fxSDK add-in.", C_BLACK, C_NONE);
extern image_t img_brouillard;
dimage(0, 9, &img_brouillard);
for(int i = 0; i < 16; i++)
{
dsubimage(4 + 16 * (i&7), 32 + 16 * (i>=8), &img_brouillard,
8 * i, 0, 8, 8, DIMAGE_NONE);
}
dupdate();
getkey();
return 1;
}
Citer : Posté le 06/08/2019 18:25 | #
Super, ça marche, merci beaucoup !
Citer : Posté le 08/08/2019 23:07 | #
Bon... j'ai intégré la pull request de Milang (merci encore !) et commencé à tester dclear() avec un dma_memset().
La première chose à noter est que le DMA part avec un désavantage. Pour memset(), la version CPU naïve contient l'opérande de remplissage dans un registre donc tous les accès à la RAM sont faits en écriture. Le DMA, à l'inverse, est obligé de relire l'opérande à chaque cycle de lecture/écriture et fait donc deux fois plus d'accès en RAM.
Sur la même taille de 4 octets par accès, le DMA met donc 15 ms alors que la version CPU naïve met 6 ms.
Heureusement le DMA peut copier jusqu'à 32 octets par bloc, mais ça nous amène aussi à 6 ms.
La solution que j'ai trouvée est de placer l'opérande source dans une mémoire plus rapide que la RAM ; et là ça se complique. Principalement il y en a deux : la mémoire RS et la mémoire IL. Quand je place mon opérande dans la mémoire RS, le transfert se complète en 2.5 ms. Cependant la mémoire RS est utilisée pour des choses critiques comme le redémarrage et il est hors de question d'y toucher sur des add-ins en production. Quand je place l'opérande en mémoire IL, les accès par le DMA freezent.
J'ai des pistes pour avancer un peu mais c'est pas gagné tout de suite. D'un autre côté la mémoire IL est très rapide et est un super plan pour mettre du code ou des données critiques, donc ça vaut le coup de rechercher.
Notez que pour memcpy(), cette fois-ci le CPU perd son avantage car il est lui aussi obligé de lire les données en RAM, en plus de lire le code en ROM (mais pas longtemps car le cache prend le relai je suppose).
Enfin, je cherche vaguement la possibilité qu'il y ait un 2D-DMA dans le microprocesseur, qui pourrait copier des zones non continues pour afficher rapidement des images de n'importe quelle taille. En effet avec le DMA on ne peut qu'afficher des images qui font toute la largeur de l'écran, à savoir 396 pixels, c'est assez restrictif. SimLo n'indique pas de 2D-DMA dans sa doc mais ça ne coûte rien d'en chercher un je suppose.
Voilà voilà, un peu de recherche en perspective.
Citer : Posté le 09/08/2019 14:31 | #
De toute façon, même si le temps pris par le dma est supérieur, cela ne fait rien si on peut faire autre chose en même temps
Citer : Posté le 09/08/2019 14:53 | #
Well, pas tout à fait, parce que seuls les cycles de calculs sont vraiment économisés. Il n'y a qu'un seul bus et c'est chacun son tour. Tous les cycles où tu fais des accès mémoire, le DMA ne peut pas tourner. De plus, c'est pas forcément codé de façon à te permettre de faire autre chose en même temps... x_x
J'ai progressé. En cherchant un peu j'ai découvert que le problème qui se pose quand j'utilise la mémoire IL comme source est en fait une erreur d'adresse juste après la fin du transfert. C'est assez bizarre, et les effets dépendent aussi du channel DMA utilisé. Pour l'instant j'ai un contournement qui consiste à faire un transfert sans interruptions, et ça marche bien !
Donc dclear() ne prend plus 6 ms mais 2.5 ms. Yay !
Côté un peu moins bien maintenant, j'ai voulu tenter de faire une copie d'une image en plein écran vers la VRAM avec le DMA. C'est très facile à coder, mais un problème subsiste : l'image est dans la ROM, plus précisément dans la zone de la ROM qui est mappée en userspace... et n'est donc pas forcément continue sur le stockage physique, selon les caprices du système de fichiers. Or le DMA interagit quasi-exclusivement avec l'espace d'adressage physique. Et donc, la copie n'est pas possible dans le cas général...
Je vais aller voir dans le TLB quelle taille font les pages et comment elles sont agencées mais je pense que c'est 64k, et qu'une image en plein écran prend donc 3 pages. La continuité n'est donc pas garantie. On peut réfléchir à découper le transfert en 3 si l'image est extrêmement bien alignée, mais ça reste très fin. Ce ne sera sans doute pas le comportement par défaut...
Ah et btw, j'ai mesuré avec libprof le temps de dessin, exactement comme Darks le suggérait. Comme prévu, c'est 24.8 ms, soit un poil plus que 40 FPS. Avec le dclear() et les épées par-dessus, on passe en-dessous donc le programme n'arrive plus à suivre les entrées clavier (qui sont à 40 Hz par défaut dans gint). Je vais continuer de chercher des optimisations pour améliorer ça au bas niveau qu'est gint, pour que vos applications bénéficient des meilleures performances possibles.
Au passage, pour les fonctions qui écrivent directement en RAM, la facteur limitant est la vitesse de la RAM donc les optis comme dérouler des boucles pour réduire le temps CPU n'ont quasiment aucun effet.
Citer : Posté le 17/08/2019 20:02 | #
J'ai un problème en utilisant le dma :
J'ai un zbuffer que je dois effacer à chaque frame. Ce buffer est aligné sur 32 octets grâce aux fonctions suivantes :
static void* buffer_malloc(uint_fast16_t size)
{
void *mem = malloc(size+ALIGN+sizeof(void*));
void **ptr = (void**)((uintptr_t)(mem+ALIGN+sizeof(void*)) & ~(ALIGN-1));
ptr[-1] = mem;
return ptr;
}
static void buffer_free(void *ptr)
{
free(((void**)ptr)[-1]);
}
Pour effacer le buffer à chaque frame j'utilise la fonction suivante :
void FE_zbuffer_clear()
{
if (isSH3())
{ // effacer avec le CPU
uint_fast16_t indice;
for (indice = 0; indice < size_uint32; indice ++)
address[indice] = clearval[0];
}
else
{ // effacer avec le DMA
dma_transfer(0, DMA_32B, size_blocks, &clearval, DMA_FIXED, address, DMA_INC);
}
}
Logiquement, je copie donc mon tableau de 4 octets dans le zbuffer qui est aligné sur 32 octets.
Enfin, j'attends par sécurité que le transfert s'achève avec dma_transfer_wait(0); avant d'écrire dedans
Cependant, lors des tests, je m'aperçois que les valeurs présentes dans le zbuffer avec le memset du dma ne sont pas celles obtenues avec l'effacement du cpu >_<
Quelle est l'erreur dans mon utilisation du dma ?
Ajouté le 17/08/2019 à 20:08 :
J'ajoute que *src (clearval) est également aligné sur 32 bits grâce à cette fonction
Citer : Posté le 18/08/2019 21:06 | #
Je te fais confiance sur l'allocation ; n'oublie pas que tu peux simplement écrire __attribute__((aligned(32))) uint16_t zbuffer[...] si tu peux l'allouer en statique. Vérifie juste au cas où que le pointeur est bon...
clearval devrait être aligné sur 32 octets, tu peux justement utiliser cette technique :
GALIGNED(32) GSECTION(".rodata") static const int32_t clearval[8]={3000,3000,3000,3000,3000,3000,3000,3000}; // je remplis le buffer avec la valeur 3000
Et au passage le placer explicitement en ROM ne fait pas de mal.
Sinon ça m'a l'air légitime...
Citer : Posté le 18/08/2019 22:43 | #
L'allocation statique, j'aimerais bien, mais je ne suis pas sûr qu me cela fonctionne pour 32 768 octets d'un coup
Sinon merci pour tes conseils, j'essaierai la semaine prochaine
Citer : Posté le 19/08/2019 10:17 | #
L'allocation statique, j'aimerais bien, mais je ne suis pas sûr qu me cela fonctionne pour 32 768 octets d'un coup
Tu peux utiliser la zone statique sur SH4, elle fait 64k contre 8k sur SH3. Quitte à modifier un poil le linker script...
Sinon tu as la fin de la RAM qui est semble-t-il libre.
Citer : Posté le 19/08/2019 11:31 | #
Cela me parait une bonne option.
Cependant, il y a des points qui m'échappent :
Si j'alloue statiquement un tableau de 32 ko, cette opération ne fonctionnera jamais sur les modeles sh3 et je ne sais pas du tout comment modifier le linker script
Citer : Posté le 19/08/2019 11:59 | #
Les SH3 disposent de la deuxième moitité inutilisée de RAM. Tu peux certainement juste faire :
ce qui te place tout à la fin de la RAM. Faudra juste vérifier que c'est libre sur la Graph 35+E II (de mémoire oui, mais ne me crois pas sur parole avant de tester sur cette machine) et c'est bon.
Citer : Posté le 19/08/2019 12:17 | #
Mais c'est genial ça !
Je code ça tout de suite.
Quand à la graph 35 e II, ben je n'en ai pas, donc ce sera aux risques et perils du premier heureux (ou pas
Ajouté le 26/08/2019 à 15:12 :
J'ai l'impression d'avoir trouvé un bug dans le dma, probablement au niveau de la fonction dma_transfer_wait
#include <gint/keyboard.h>
#include <gint/dma.h>
#include <gint/std/stdio.h>
#include <gint/defs/attributes.h>
#define size 32768
#define clear_val 0xFFFFFFFF
GALIGNED(32) GSECTION(".rodata") static int32_t clear_vals[8]={clear_val,clear_val,clear_val,clear_val,clear_val,clear_val,clear_val,clear_val};
static int32_t *clear_zone = (void *)0x88080000 - size;
int main(void)
{
clear_zone[size/4-1]=0;
dma_transfer(0,DMA_32B,size/32,clear_vals,DMA_FIXED,clear_zone,DMA_INC);
dma_transfer_wait(0);
int val=clear_zone[size/4-1];
char txt[10];
sprintf(txt,"%d",val);
dclear(C_WHITE);
dtext(1, 1, txt, C_BLACK, C_NONE);
dupdate();
getkey();
return 1;
}
Alors que le programme devrait m'afficher quelque chose comme -1, il me retourne 0
(J'execute le code sur une g35++ sh4 2.05.2201)
Ajouté le 26/08/2019 à 15:24 :
ça se précise !
le problème ne vient pas de dma_transfer_wait, mais de dma_transfer
#include <gint/keyboard.h>
#include <gint/dma.h>
#include <gint/std/stdio.h>
#include <gint/defs/attributes.h>
#define size 32768
#define clear_val 0xFFFFFFFF
GALIGNED(32) GSECTION(".rodata") static int32_t clear_vals[8]={clear_val,clear_val,clear_val,clear_val,clear_val,clear_val,clear_val,clear_val};
static int32_t *clear_zone = (void *)0x88080000 - size;
int main(void)
{
clear_zone[size/4-1]=0;
dma_transfer(0,DMA_32B,size/32,clear_vals,DMA_FIXED,clear_zone,DMA_INC);
//dma_transfer_wait(0);
while (clear_zone[size/4-1]==0)
0;
int val=clear_zone[size/4-1];
char txt[10];
sprintf(txt,"%d",val);
dclear(C_WHITE);
dtext(1, 1, txt, C_BLACK, C_NONE);
dupdate();
getkey();
return 1;
}
Ajouté le 26/08/2019 à 15:29 :
en fait, même avec dma_transfer_noint, cela ne marche pas et la calculatrice freeze
Il y a donc un problème au niveau du transfert
Citer : Posté le 26/08/2019 15:33 | #
As-tu essayé avec dma_memset() ? J'ai résolu des bugs non triviaux pour le faire marcher celui-là.
Citer : Posté le 26/08/2019 15:42 | #
dans quel header est-elle définie, je ne la vois pas ?
Citer : Posté le 26/08/2019 15:44 | #
(use "git add <file>..." to include in what will be committed)
src/core/exch.c
src/dma/memcpy.c
src/dma/memset.c
src/render-cg/dimage.c
Never mind?
Je te pousse ça dès que j'ai plus de quelques minutes...
Ajouté le 27/08/2019 à 21:30 :
Voilà, c'est poussé. N'hésite pas à essayer avec dma_memset().
Par ailleurs, j'ai eu des problèmes lorsque j'ai testé cette fonction et j'ai dû me rabattre sur le DMA1 sans interruptions. Utiliser le DMA0 ou utiliser les interruptions ne marchait pas. Ce bug ne se produisait que quand la source était la mémoire IL.
Au cas où tu ne connaisses pas encore, la mémoire IL est un bout de mémoire sur la puce qui est indépendant de la RAM et à accès rapide, surtout pour le code. Elle est associative à 4 voies et remplace typiquement la mémoire L1 des processeurs modernes. J'ai expliqué un peu les enjeux dans #168088 ; en gros quand je passe par la mémoire IL le comportement est plus erratique. DMA1 sans interrputions semble marcher.
Citer : Posté le 27/08/2019 22:27 | #
ok, je vais essayer
Je trouve quand même étrange que le channel 0 ne soit pas fonctionnel
En tout cas, cela va augmenter sensiblement les perfs je pense
Citer : Posté le 28/08/2019 09:57 | #
Je trouve quand même étrange que le channel 0 ne soit pas fonctionnel
J'ai renoncé à comprendre pour l'instant... c'est louche louche, vraiment
Je passe de 6 ms à 2.5 ms pour un dclear() qui était déjà bien optimisé donc je pense que oui. Avec un peu de chance ton nettoyage de z-buffer va prendre un petit ×3 (pas sûr après, l'optimisation du code ne compte peu-être juste pas quand c'est la fréquence de la RAM qui régit le débit).
Ajouté le 29/08/2019 à 15:33 :
Des nouvelles ? Est-ce que ça marche mieux avec dma_memset() ?
Citer : Posté le 29/08/2019 15:40 | #
alors je n'ai pas encore retesté, car comme j'ai transformé fxengine en lib j'ai choisi de le restructurer, mais je vais reprendre mon programme de test et regarder
D'ailleurs, du coup j'ai du réécrire la déclaration dans mon fichier source, car à ma connaissance la fonction n'est dans aucun header
Citer : Posté le 29/08/2019 15:41 | #
Ah exact, j'ai dû oublier ça pendant le développement. Je vais m'en occuper.
Citer : Posté le 29/08/2019 15:47 | #
alors du coup, j'ai réouvert mon projet de test :
#include <gint/keyboard.h>
#include <gint/dma.h>
#include <gint/std/stdio.h>
#define SIZE (32768)
#define CLEAR_VAL (0xFFFFFFFF)
static int32_t *clear_zone = (void *)0x88080000 - SIZE;
extern void dma_memset(void *dst, uint32_t l, size_t size);
int main(void)
{
clear_zone[SIZE/4-1]=0;
dma_memset(clear_zone, CLEAR_VAL, SIZE);
char txt[10];
sprintf(txt,"%d",clear_zone[SIZE/4-1]);
dclear(C_WHITE);
dtext(1, 1, txt, C_BLACK, C_NONE);
dupdate();
getkey();
return 1;
}
mais le compilateur me dit
(.gint.blocks+0x3c): undefined reference to `dma_address_error'
Citer : Posté le 29/08/2019 15:51 | #
Ouuups xD
C'est la fonction qui déclenche le gestionnaire d'erreur quand une erreur d'adresse se produit durant un transfert DMA. Je l'ai ajoutée récemment, mais quand j'ai commit la dernière fois j'ai séparé les modifs du DMA de celles du gestionnaires d'erreur, donc le commit est incomplet...
Et bien sûr j'ai testé dans mon environnement à moi où la fonction est fournie par gintctl et du coup je m'en suis pas rendu compte...
Ajouté le 03/09/2019 à 22:37 :
Voilà, j'ai poussé tout ce qu'il fallait, à savoir les gestionnaires d'exceptions. Tu devrais pouvoir compiler maintenant, puisque j'ai fait pointer l'erreur d'adresse du DMA dessus.
Désormais, si votre code fait une opération illégale, au lieu de crasher gint affiche un message d'erreur, exactement comme une System ERROR en fait.
Si vous rencontrez un crash, alors il y a probablement un bug et un rapport de bug est le bienvenu.
Je mettrai demain des images des erreurs en question.